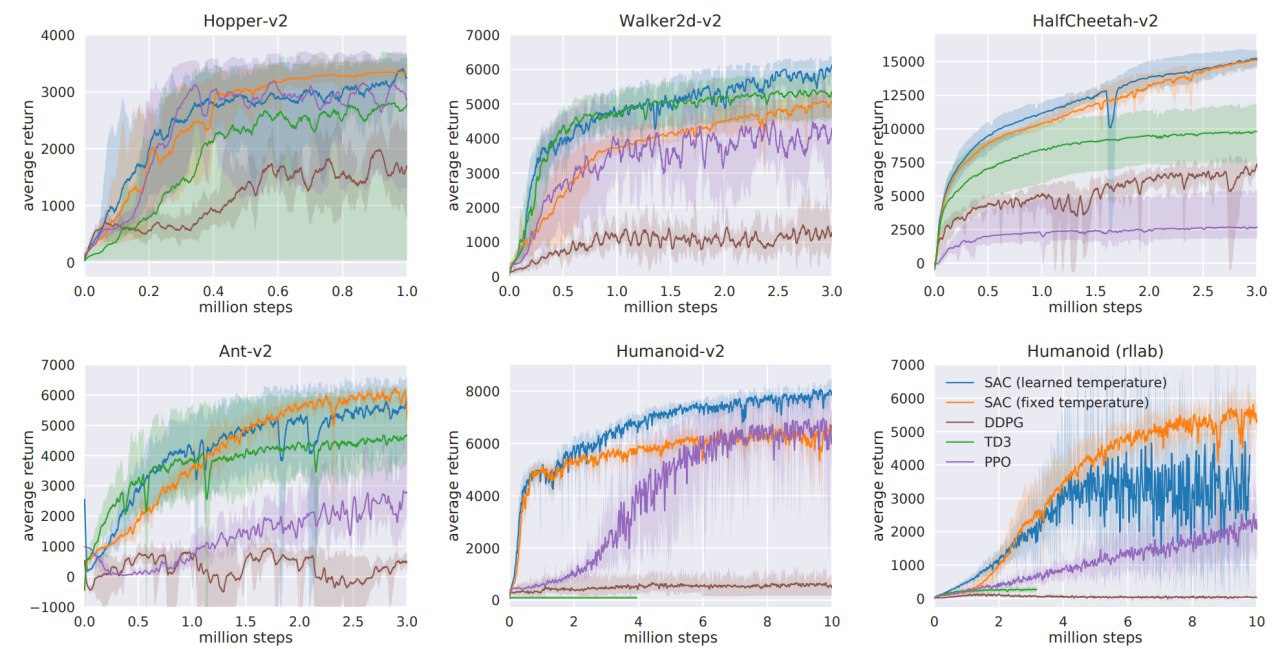
Вот здесь есть более сильные цифры для Walker и Humanoid. Там, конечно, речи о sample efficiency идти не может, но зато есть примерная оценка потолка, который можно достичь.
Вообще, мне кажется, что все Mujoco среды достаточно задраны и текущие Sota-алгоритмы близки к максимально возможным наградам.
Вот здесь есть более сильные цифры для Walker и Humanoid. Там, конечно, речи о sample efficiency идти не может, но зато есть примерная оценка потолка, который можно достичь.
Вообще, мне кажется, что все Mujoco среды достаточно задраны и текущие Sota-алгоритмы близки к максимально возможным наградам.