



DR
Size: a a a
2020 August 26

ML
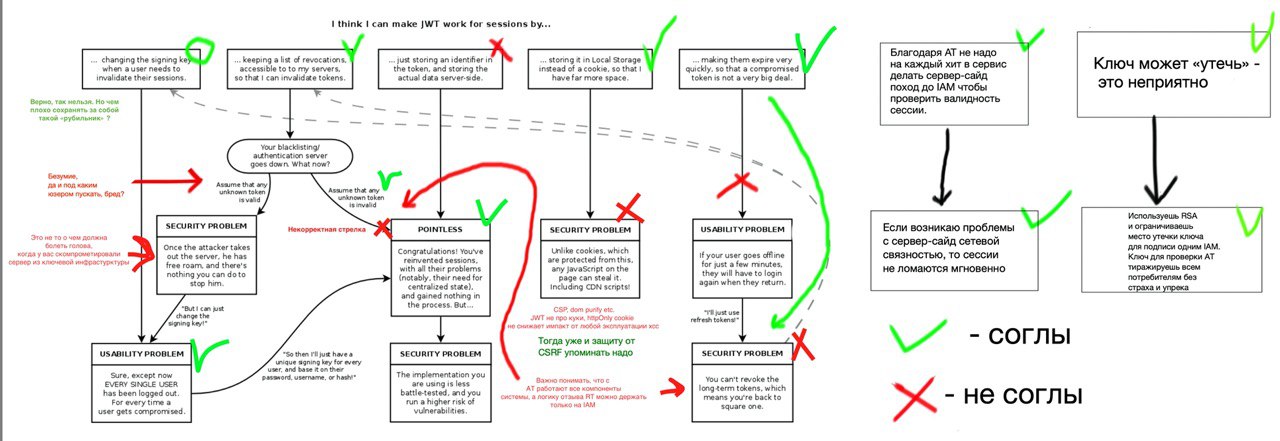
Такие мысли накидал тут, мб не все корректно пояснил. Архитектурно речь про абстрактуню разнородную большую систему
"это не то о чём должна болеть голова" не согласуется с "при потере сервер-сайд сетевой связности", в первом случае почему-то предполагается именно компрометация, в то время как во втором это просто "потеря". Либо в обоих случаях "это не то, о чём должна болеть голова", либо крестик с первого стоит убрать
M
посоны вопрос
есть средства для автоматического парсинга сваггера?
нужно чтобы
1. собирало список эндпоинтов
2. собирало шаблоны реквестов
есть средства для автоматического парсинга сваггера?
нужно чтобы
1. собирало список эндпоинтов
2. собирало шаблоны реквестов
D
посоны вопрос
есть средства для автоматического парсинга сваггера?
нужно чтобы
1. собирало список эндпоинтов
2. собирало шаблоны реквестов
есть средства для автоматического парсинга сваггера?
нужно чтобы
1. собирало список эндпоинтов
2. собирало шаблоны реквестов
В берпе расширение есть openapi что то там называется
DR
"это не то о чём должна болеть голова" не согласуется с "при потере сервер-сайд сетевой связности", в первом случае почему-то предполагается именно компрометация, в то время как во втором это просто "потеря". Либо в обоих случаях "это не то, о чём должна болеть голова", либо крестик с первого стоит убрать
Кажется речь о разных процессах. Если «моргнул» IAM, то по уже выданым АТ все сервисы останутся доступными. А вот RT все считаем невалидными и если IAM лег на долго (больше ttl AT), то и правда всех вылогинит. А в классических сессиях все еще хуже, если авторизация упала то у тебя сразу все умрут (причем еще в непонятном состоянии на пол запроса), ведь у тебя на каждый клиенский поход в сервис с кукой есть сервир-сайд поход в авторизацию типо /checksession, это твоя точка правды где все проверяют валидность сессии.
Отдельно стоит упомянуть что в этой точке правды у тебя огромная нагрузка будет (с АТ схемой ты размазываешь нагрузку на каждый сервер т.к. они проверяют сессии сами)
Отдельно замечу, что часто тебе надо довозить профили пользователей на всех потребителей и у тебя все равно сервер сайд хитты будут, но их можно хотя бы кешировать. Тут ситуативно, если продукт предполагает что так и так будут походы в базу за данными, то может и авторизацию не смысла «оптимизировать»
Отдельно стоит упомянуть что в этой точке правды у тебя огромная нагрузка будет (с АТ схемой ты размазываешь нагрузку на каждый сервер т.к. они проверяют сессии сами)
Отдельно замечу, что часто тебе надо довозить профили пользователей на всех потребителей и у тебя все равно сервер сайд хитты будут, но их можно хотя бы кешировать. Тут ситуативно, если продукт предполагает что так и так будут походы в базу за данными, то может и авторизацию не смысла «оптимизировать»
M
В берпе расширение есть openapi что то там называется
о класс спасибо
DR
"это не то о чём должна болеть голова" не согласуется с "при потере сервер-сайд сетевой связности", в первом случае почему-то предполагается именно компрометация, в то время как во втором это просто "потеря". Либо в обоих случаях "это не то, о чём должна болеть голова", либо крестик с первого стоит убрать
Если говорить про взлом, то тут в обоих схемах все плохо. Т.к. это критичная инфраструктура которая должна иметь максимум хардерингов (defence in depth) и минимальную поверхность атаки (минимум ручек АПИ + прошедших ревью). Взлом этого компонента скорее всего значит что:
-база юзеров от вас уже уехала
-любой аккаунт может быть захвачен и смены паролей,оплаты превязаноми карточками,что-то еще уже делаются злоумышленниками
-у зломышленника уже есть или скоро будет сетевой доступ в прод сегмент сети
Разницы JWT и сессии я тут не вижу принципиальной, но то что кто-то не смог войти в свой аккаунт тут наименьшая из твоих проблем(а может даже и большая удача т.к. кто там ломиться уже неясно), в этом мысль
-база юзеров от вас уже уехала
-любой аккаунт может быть захвачен и смены паролей,оплаты превязаноми карточками,что-то еще уже делаются злоумышленниками
-у зломышленника уже есть или скоро будет сетевой доступ в прод сегмент сети
Разницы JWT и сессии я тут не вижу принципиальной, но то что кто-то не смог войти в свой аккаунт тут наименьшая из твоих проблем(а может даже и большая удача т.к. кто там ломиться уже неясно), в этом мысль
ps

👾0
имеем сервер на java (tomcat), грузить в одной из форм можно все что угодно, пыхофайлы грузятся но интерпритатор не установлен на сервере, html изи грузится и рендерится, .jsp грузится но не имеет прав исполнения
👾0
что можно предпринять в данной ситуации?
ps
что можно предпринять в данной ситуации?
шелл
👾0
perl -E 'my @drugs = glob ("/home/plants/*"); say sort "@drugs"' | xargs -n 1 | nl
шелл
это я понял, но .jps не исполняется на сервере
ps
это я понял, но .jps не исполняется на сервере
исполни то, что исполняется
👾0
html )
ps
перл исполняется?
👾0
о точно, забыл за него
A
а как ты запускаешь?
BF
имеем сервер на java (tomcat), грузить в одной из форм можно все что угодно, пыхофайлы грузятся но интерпритатор не установлен на сервере, html изи грузится и рендерится, .jsp грузится но не имеет прав исполнения
Залей html с js, будет xss
👾0
не исполняется perl
👾0
Залей html с js, будет xss
хотел докрутить до шела