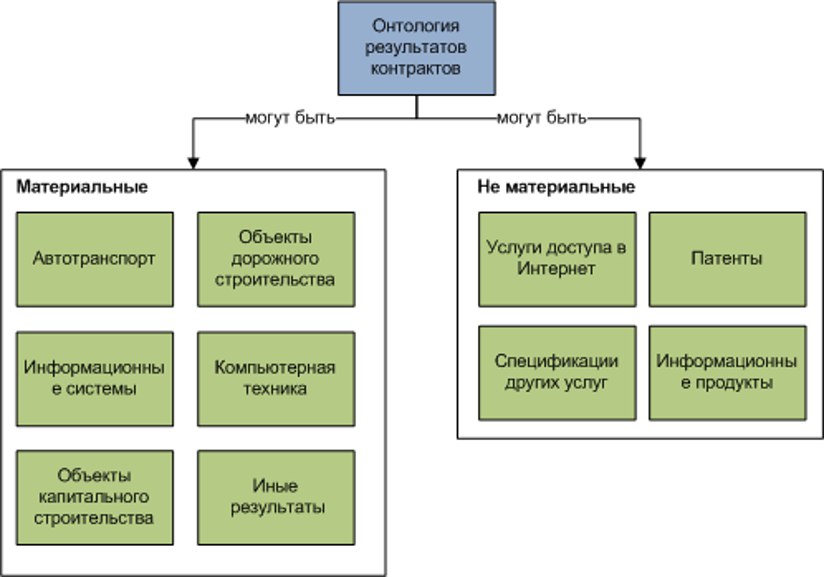
В блоге Facebook заметка о Nemo [1], их внутреннем инструменте для Data Discovery, продукте котором можно назвать каталогом данных, но правильнее называть инструментом обнаружения и использования данных для работы внутренних команд. Они не первые создавшие такой инструмент в Airbnb, Lyft, Netflix, и Uber есть свои аналогичные продукты. На рынке существует несколько десятков продуктов по созданию каталогов данных все из которых можно разделить на три условные категории:
- внутрикорпоративные каталоги данных (от метаданных до баз/таблиц/озер данных)
- порталы открытых данных
- порталы для открытых научных репозиториев
При этом именно внутрикорпоративные каталоги сейчас переживают бум расцвета, но со своей сильной спецификой на том что они ориентированы на интеграцию с разного рода корпоративными системами хранения и продуктами. И, как правило, предусматривают строгий контроль метаданных и их гармонизацию.
Есть определить основные характеристики этих всех продуктов то их отличия можно описать следующим образом.
Порталы открытых данных
- почти всегда публичны
- предполагают отсутствие контроля за первоисточниками
- включают метаданные характеризующие доступность данных, например, лицензии
- интегрированы на уровне сбора метаданных (OAI-PMH, CKAN Metadata и др)
- иногда предусматривают, но почти никогда не обеспечивают на 100% гармонизацию метаданных
- либо включают очень много наборов данных или фокус на конкретную область их применения (отрасль)
Порталы открытых научных данных (репозитории научных данных)
- почти всегда публичны
- не контролируют первоисточники, но устанавливают требования к структуре метаданных публикуемых материалов
- чаще всего созданы на базе репозиториев научных работ или связаны с ними общей логикой формирования метаданных
- почти всегда включают регистрацию уникальных ссылок (пермалинков) и инструменты генерации цитат в выбранном стиле для научного цитирования
- интегрированы на уровне сбора метаданных (OAI-PMH)
Внутрикорпоративные каталоги данных / порталы данных и системы метаданных
- непубличны
- интегрированы с внутренними озерами и данных и хранилищами данных
- предполагают полный или преимущественный контроль за хранимыми данными
- включают описания бизнес-словаря метаданных и гармонизацию метаданных
Из всего вышеперечисленного именно внутрикорпоративные каталоги данных - это самый трудоёмкий формат работы с данными именно из-за огромной работы с метаданными. Она требует выстраивания процессов так чтобы все изменения в таблицах регистрировались в каталоге в специальной форме описания метаданных. Это хорошо работает при небольшом числе контролируемых внутренних источников и плохо работает при большом числе внешних неконтролируемых источников данных.
Из открытых инструментов с открытым исходным кодом есть Apache Atlas [2] выступающий как репозиторий метаданных для контроля уровня чувствительности данных и Amundsen [3], для удобства специалистов по data science
Ссылки:
[1]
https://engineering.fb.com/data-infrastructure/nemo/[2]
https://atlas.apache.org[3]
https://github.com/amundsen-io/amundsen#opendata #data #opensource