



СВ

взял 0.01 от датасета. Я в y_pred ожидал увидеть одномерный массив. Хотел classification_report распечатать
Size: a a a
СВ
DD
EZ
СВ

AB
СВ
СВ

СВ
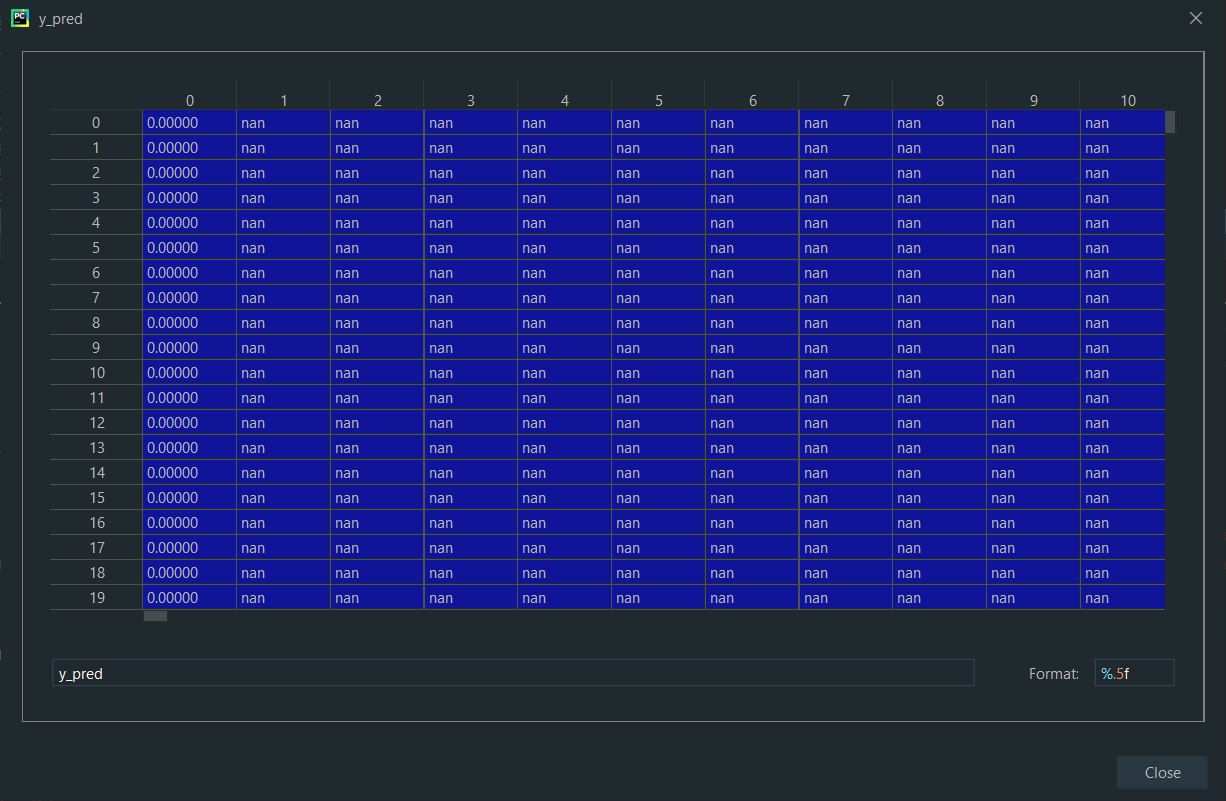
DD
СВ
DD
import pandas as pd
from statsmodels.discrete.discrete_model import MNLogit
df = pd.DataFrame({'x': [1,2,3,4,5,6,7,8,9], 'y': [1,2,3,1,2,3,1,2,3]})
model = MNLogit.from_formula('y~x', df)
result = model.fit()
result.predict(df)
СВ
import pandas as pd
from statsmodels.discrete.discrete_model import MNLogit
df = pd.DataFrame({'x': [1,2,3,4,5,6,7,8,9], 'y': [1,2,3,1,2,3,1,2,3]})
model = MNLogit.from_formula('y~x', df)
result = model.fit()
result.predict(df)
СВ
import pandas as pd
from statsmodels.discrete.discrete_model import MNLogit
df = pd.DataFrame({'x': [1,2,3,4,5,6,7,8,9], 'y': [1,2,3,1,2,3,1,2,3]})
model = MNLogit.from_formula('y~x', df)
result = model.fit()
result.predict(df)
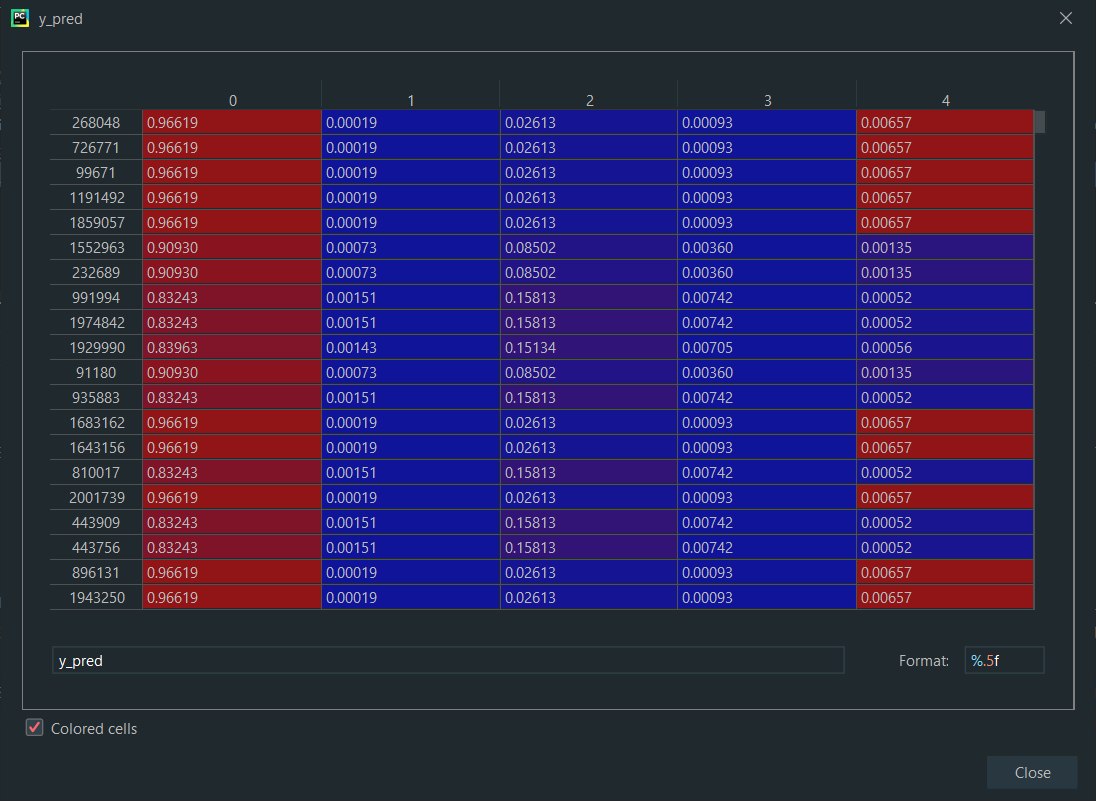
DD
СВ
print(classification_report(y_pred= y_pred.max(axis=1), y_true=test["PKT_CLASS"]))DD
DD
