A
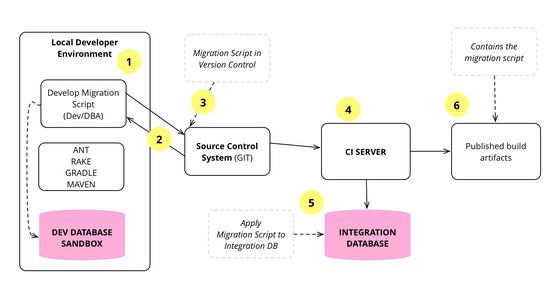
Я бы не сказал что мы специально тестируем именно момент отката. Это происходит само собой - т.е. у нас есть 1 RC Stage, куда QA выкатывает новую фичу и в рамках нее схема меняется на новую. Когда QA выкатывает другую фичу, то предыдущая должна успешно откатиться и потом накатиться новая. И так несколько раз за день.
понятно, спасибо! выглядит немного опасно) стало интересно в фразе “иногда приходится все стопать и руками что-то докручивать (тьфу-тьфу, давно так не делали)” иногда и давно - это как?