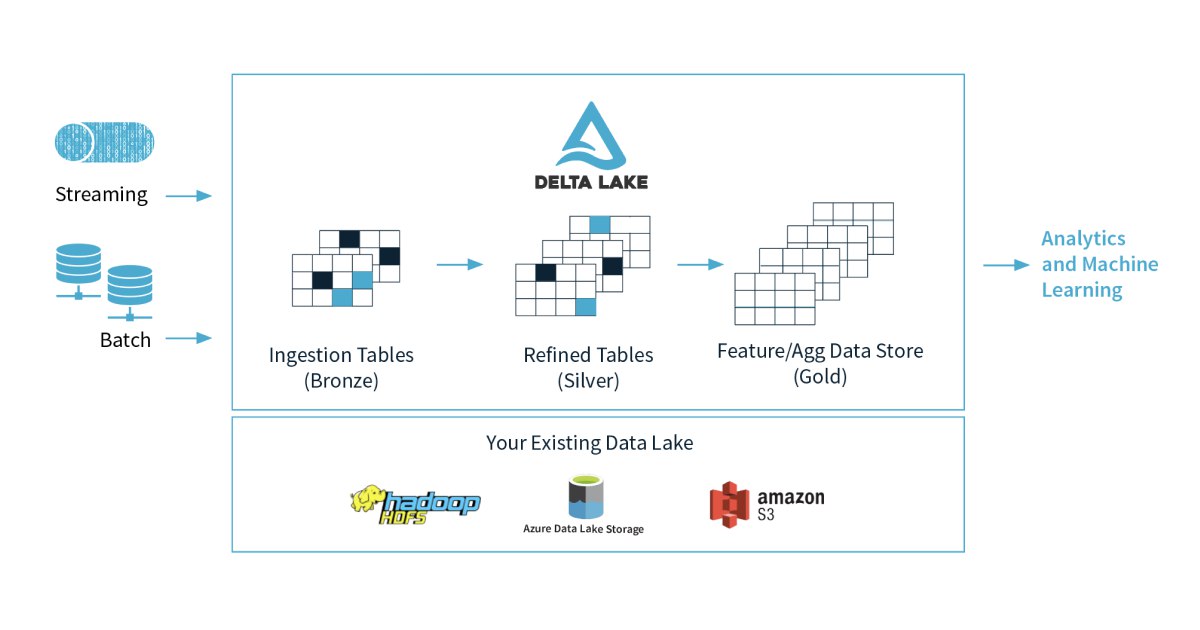
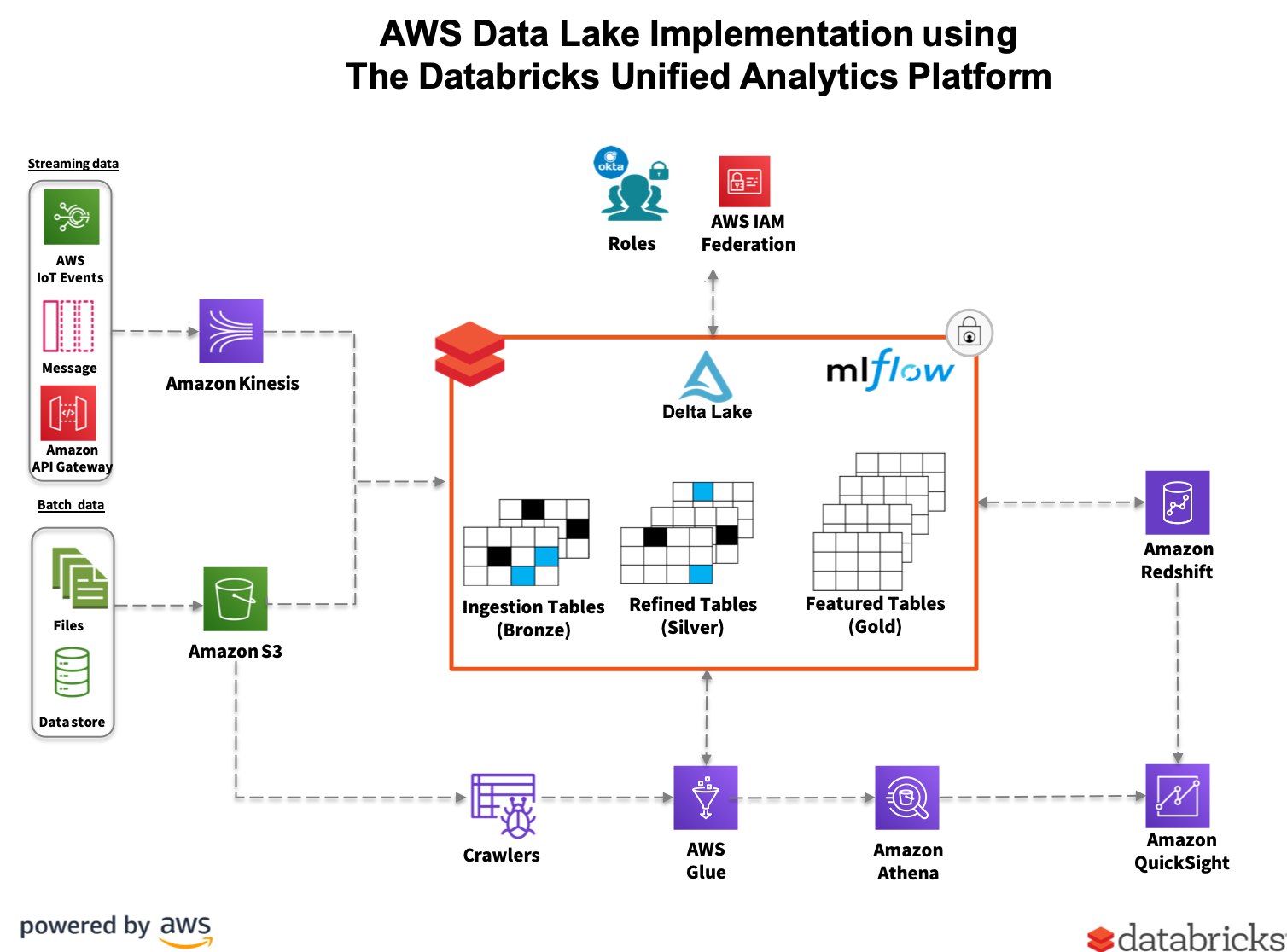
Мы используем дельту, да только это же работа с файлами напрямую, так я и без дельты могу .save сделать. Сейчас у нас вся мета в глю, работаем как с таблицами хайва. Не то, чтобы это прям необходимость, но саентологи вроде заинтересованы, да и хочется более плавного перехода. Пока действительно вижу, что будем писать файлы и повесим внешние таблицы сверху, если нужно.
Мы используем дельту, да только это же работа с файлами напрямую, так я и без дельты могу .save сделать. Сейчас у нас вся мета в глю, работаем как с таблицами хайва. Не то, чтобы это прям необходимость, но саентологи вроде заинтересованы, да и хочется более плавного перехода. Пока действительно вижу, что будем писать файлы и повесим внешние таблицы сверху, если нужно.
Но ведь в целом Спарк не про это, а про работу с разными источниками данных. Какая у вас задача что нужен именно метастор типа хайва?
Зачем работать с разными источниками данных, чтобы сливать их хрен знает куда? Спарк - самый удобный способ интеграции данных в хранилище, но само хранилище тоже должно быть удобным, а удобнее sql metastore ещё пока ничего не придумали
Кто нибудь знает почему ‘’’df_driver.withColumn('requestTime',date_format(to_timestamp(df_driver.requestTime, "yyyy-MM-dd'T'HH:mm:ss.SSSSSS"), "yyyy-MM-dd'T'HH:mm:ss.SSSSSS"))’’’ даёт null в pyspark? Дата выглядит так 2020-07-01T13:00:03.629491 .null значения возникают,когда начинаю указывать миллисекунды
Кто нибудь знает почему ‘’’df_driver.withColumn('requestTime',date_format(to_timestamp(df_driver.requestTime, "yyyy-MM-dd'T'HH:mm:ss.SSSSSS"), "yyyy-MM-dd'T'HH:mm:ss.SSSSSS"))’’’ даёт null в pyspark? Дата выглядит так 2020-07-01T13:00:03.629491 .null значения возникают,когда начинаю указывать миллисекунды