



N
У него есть функция , которая по ключу возвращает номер партиции. В этом его весь смысл и состоит.
Size: a a a
N
PK
Sa
PK
Sa
Sa
АЖ
Sa
АЖ
Sa
А
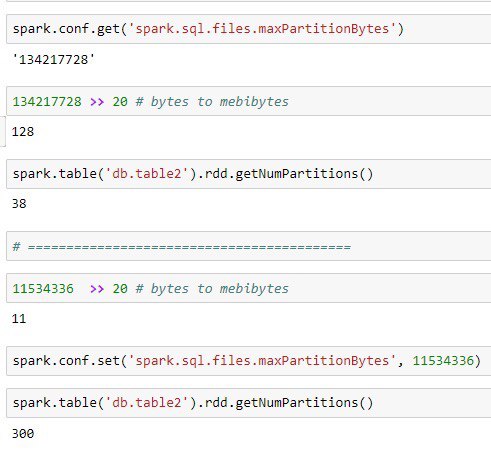
spark.sql.files.maxPartitionBytes 134217728 (128 MB) The maximum number of bytes to pack into a single partition when reading files. This configuration is effective only when using file-based sources such as Parquet, JSON and ORC.
Sa
spark.sql.files.maxPartitionBytes 134217728 (128 MB) The maximum number of bytes to pack into a single partition when reading files. This configuration is effective only when using file-based sources such as Parquet, JSON and ORC.
А
A🦕
spark.sql.files.maxPartitionBytes 134217728 (128 MB) The maximum number of bytes to pack into a single partition when reading files. This configuration is effective only when using file-based sources such as Parquet, JSON and ORC.
GT
DZ
DZ
GP
GP
GP
