



GP
Size: a a a
2021 April 06

PK
Да я ж звал тя ...
А я-то тут при чем? ))
ПФ
Да я ж звал тя ...
Ты перепутал Пашу с Холден )
GP
Круто! А на Moscow Spark Холден выступать отказалась ))
Матей Захария не пошёл кстати, но прислал людей взамен
АЖ
Ты перепутал Пашу с Холден )

PK
Матей Захария не пошёл кстати, но прислал людей взамен
Он плитку продает теперь, некогда ему
GP
АЖ
Он плитку продает теперь, некогда ему
многослойную
ПФ
восемь нормалей от глаза?
ИК
Продолжаю размышления, может есть абстракция типа RDD => Seq[RDD], и можно на каждый RDD применить полученную ShuffleDependency? Но в конечном итоге они снова должны стать одним RDD, что их Union-ом склеивать?
Ну ладно, предположим, получилось сделать Seq[RDD], но стейдж всё равно останется один, значит, нужен соответствующий план, чтобы каталист знал, как его проходить. Получается, надо писать практически всю реализацию, и всё для того, чтобы не раскидывать одновременно сотни терабайт по дискам на экзекуторах
ИК
Ну ладно, предположим, получилось сделать Seq[RDD], но стейдж всё равно останется один, значит, нужен соответствующий план, чтобы каталист знал, как его проходить. Получается, надо писать практически всю реализацию, и всё для того, чтобы не раскидывать одновременно сотни терабайт по дискам на экзекуторах
Походу, надо попробовать чекпоинтить ShuffledRowRDD во временную директорию, и посмотреть хотя бы, что будет с Shuffle Write
ИК
Походу, надо попробовать чекпоинтить ShuffledRowRDD во временную директорию, и посмотреть хотя бы, что будет с Shuffle Write
До эксперимента дело так и не дошло, но, судя по коду, шафл не уменьшится, потому что пока запись последнего шафл-файла не закончена, в каждой секции RDD могут появиться новые записи. А значит, в той же джобе невозможно начать новый стейдж, сколько ни чекпоинти RDD в этой джобе
Есть мысль, что надо смотреть в сторону External shuffle service
Есть мысль, что надо смотреть в сторону External shuffle service
JF
привет 🙂 помогите, пожалуйста, с запросом. А то уже запуталась. Есть такой датафрейм, как из всех дупликатов оставить только тот, у кого state NY. Ключ по name, department. Спасибо 🙏
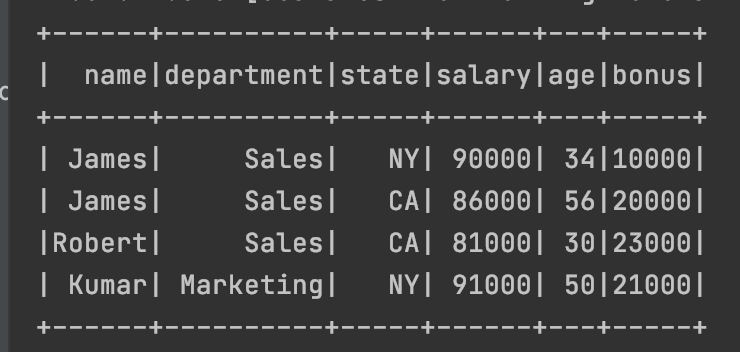
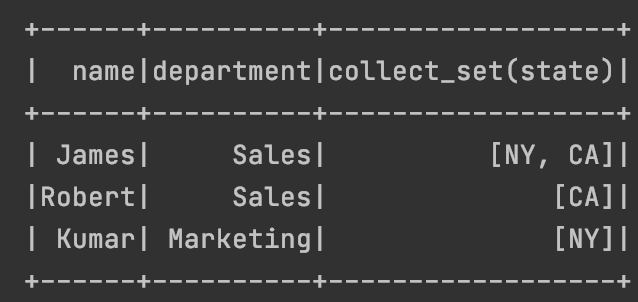
JF
а нужно получить:

JF
James Sales дублирован
А
Row_number over?
AK
И кейсом обмазаться))