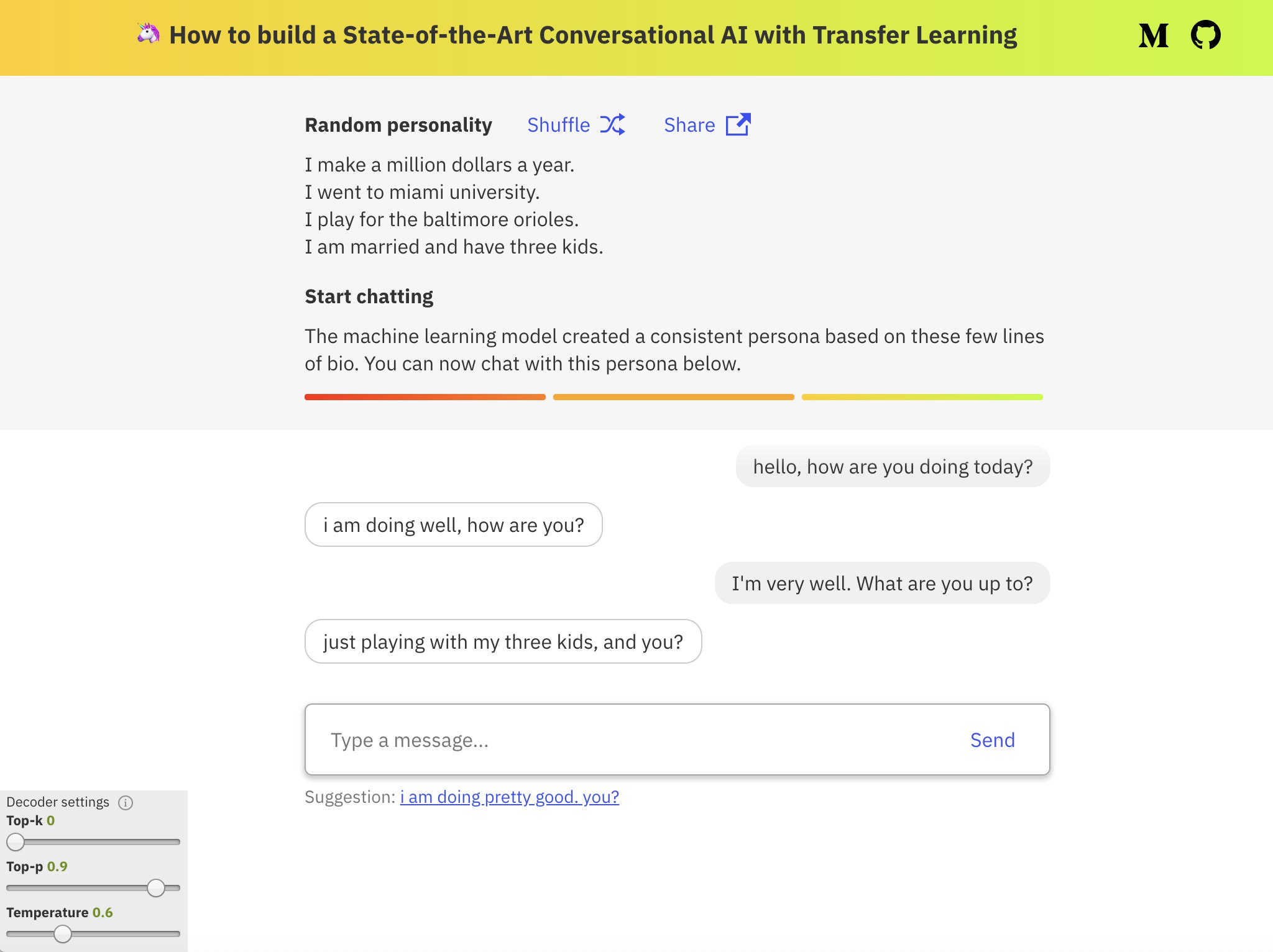
Нейросеть «Сбера» ruGPT-3 стала вдвое «умнее» |
cnews
«Сбер» продолжает развивать русскоязычную нейросеть ruGPT-3, которая способна генерировать очень сложные осмысленные тексты всего лишь по одному запросу на «человеческом» языке. С момента презентации нейросети на AI Journey 2020 количество её параметров выросло почти вдвое — с 760 млн до 1,3 млрд. Это огромный шаг вперёд в обработке естественного языка методами искусственного интеллекта в России.
GPT-3 — крупнейшая языковая модель в мире, разработанная компанией OpenAI для решения любых задач на английском языке. На русском языке, более сложном с точки зрения структуры, до появления ruGPT-3 аналогичных качественных моделей не существовало.
Отечественная GPT-3 постоянно обучается на суперкомпьютере Сбера «Кристофари» на гигантском массиве данных, так что её возможности растут с каждым днём
RuGPT-3 может не только создавать тексты любого профиля (новости, романы, стихи, пародии, техническую документацию и так далее), но также исправлять грамматические ошибки, вести диалоги и писать программный код. По сути, это прообраз общего, или сильного, искусственного интеллекта (Artificial General Intelligence, AGI), способного решать разноплановые задачи в различных сферах деятельности.