Из-за чего может быть ошибка "NotFoundError: Key cls/predictions/transform/dense/kernel not found in checkpoint" ? Я пытаюсь вызвать предтренированную модель SBERT: load_trained_model_from_checkpoint(config_path, checkpoint_path, training=True). Если же training=False, то все ОК. Модель выводится. Содержимое модели под tensorflow использую как есть:
Из-за чего может быть ошибка "NotFoundError: Key cls/predictions/transform/dense/kernel not found in checkpoint" ? Я пытаюсь вызвать предтренированную модель SBERT: load_trained_model_from_checkpoint(config_path, checkpoint_path, training=True). Если же training=False, то все ОК. Модель выводится. Содержимое модели под tensorflow использую как есть:
Подскажите как в BERT запихнуть текст больше 512 токенов, интересует задача sentimental analysis. Есть датасет с размеченными новостями, но тексты больше 512 токенов.
Подскажите как в BERT запихнуть текст больше 512 токенов, интересует задача sentimental analysis. Есть датасет с размеченными новостями, но тексты больше 512 токенов.
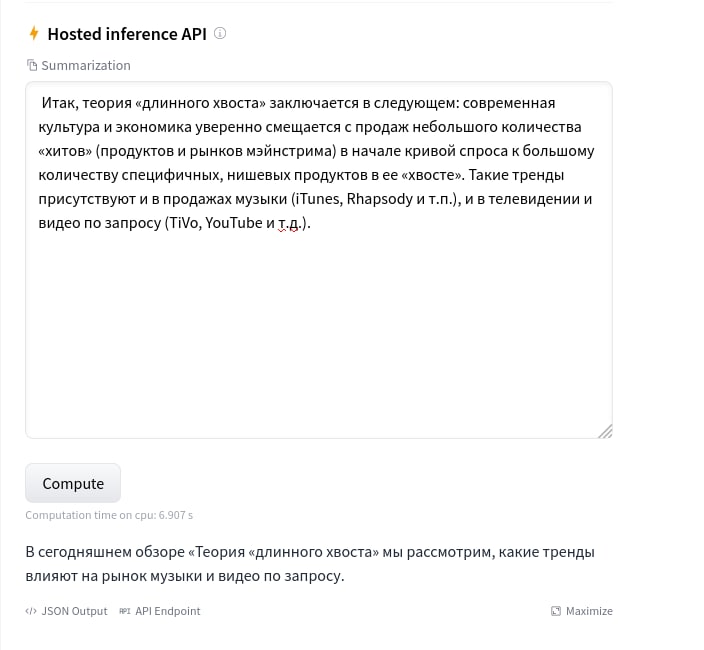
Использовать перед ним другую модель для суммаризации?
Подскажите как в BERT запихнуть текст больше 512 токенов, интересует задача sentimental analysis. Есть датасет с размеченными новостями, но тексты больше 512 токенов.
Подскажите как в BERT запихнуть текст больше 512 токенов, интересует задача sentimental analysis. Есть датасет с размеченными новостями, но тексты больше 512 токенов.
Иногда берут перекрывающиеся 512-токенные окна, а потом усредняют результат
Подскажите как в BERT запихнуть текст больше 512 токенов, интересует задача sentimental analysis. Есть датасет с размеченными новостями, но тексты больше 512 токенов.
Проще всего порезать текст на пересекающиеся кусочки и прогнать через Берт каждый в отдельности, а потом результат как-то агрегировать
Подскажите как в BERT запихнуть текст больше 512 токенов, интересует задача sentimental analysis. Есть датасет с размеченными новостями, но тексты больше 512 токенов.
Нормальные новости имеют структуру "перевернутой пирамиды", все самое важное в lead. Для "просто" аннотации хватит 512 токенов. Сложнее для аннотации по запросу.
Нормальные новости имеют структуру "перевернутой пирамиды", все самое важное в lead. Для "просто" аннотации хватит 512 токенов. Сложнее для аннотации по запросу.