NK
Stephan De Spiegeleire
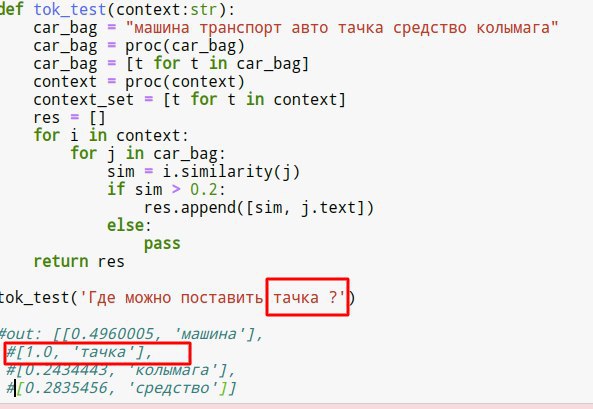
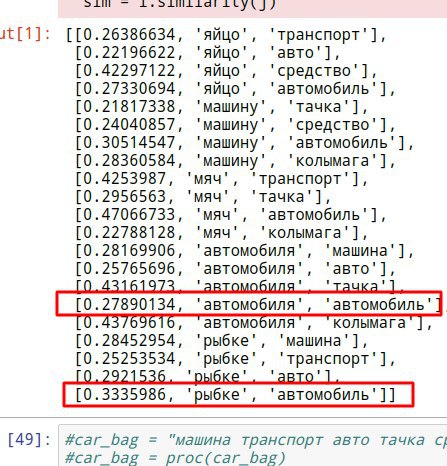
Question to the group: does anybody know of any code that can generate all cases of Russian nouns? So basically the reverse of lemmatization: you give the code a noun in nominative singular; and the code returns all other grammatical cases of that noun
pymorphy