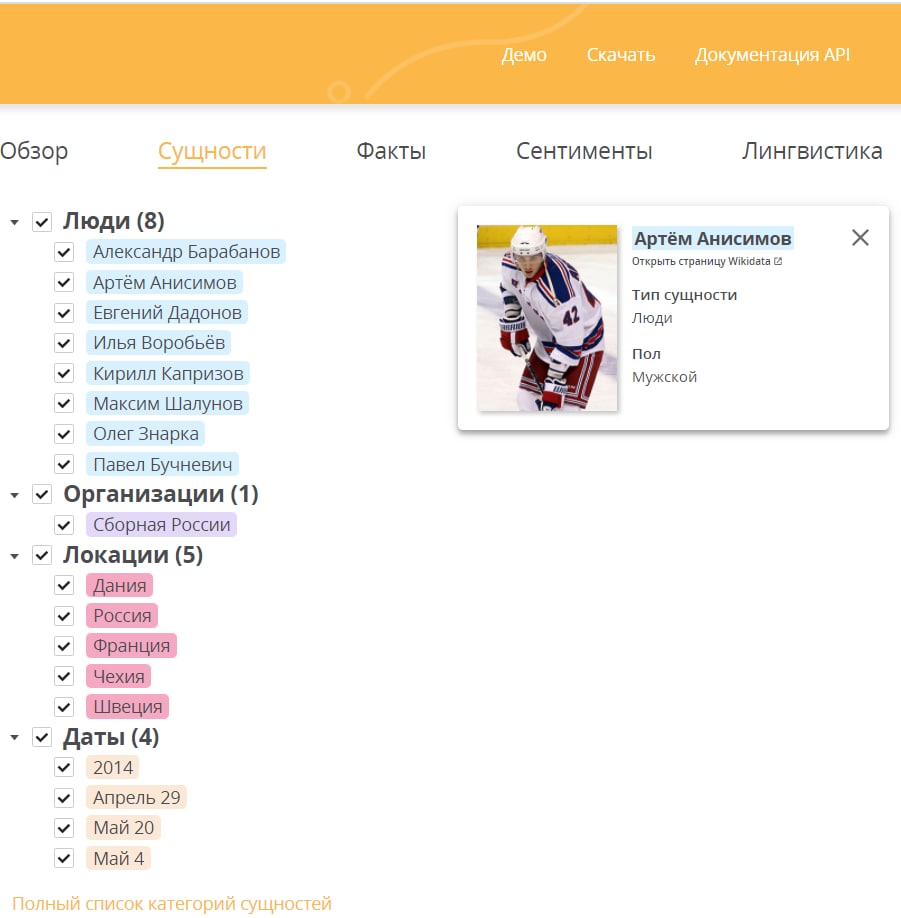
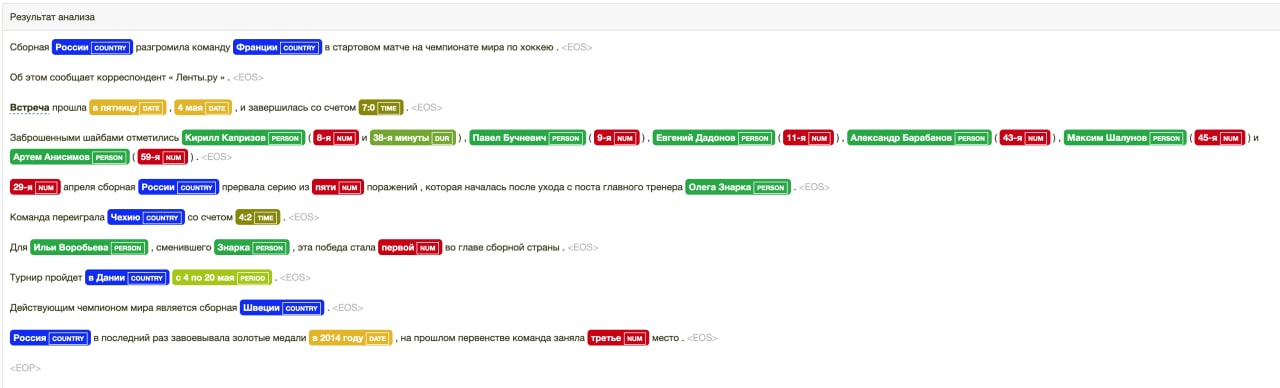
Полагаю вы обучались больше на новостном датасете.
Николай, Мегапьютер - один из пионеров технологий анализа текста (с 2000-х годов поставляем системы клиентам). У нас реализованы две альтернативные (ну или взаимодополняющие) технологии для извлечения сущностей. Результаты, которые Вы видите в демке получены с помощью системы, работающей на лингвистических правилах. Ее преимущество в более высокой (на два порядка) скорости работы. Для промышленных применений системы высокая скорость анализа может оказаться критически важным преимуществом. Другой подход, реализованный в нашей основной системе PolyAnalyst (в дополнение к системе на правилах) основан на машинном обучении (BERT, RNN, etc.). Он как раз обучается на разных корпусах и дает результаты более-менее похожие на Deep Pavlov. Но все зависит от текстов. На разных текстах у Вас то одни, то другие системы будут давать лучшие результаты. Еще, Вам может будет интересно сравнить, как система сможет распознавать ко-референции, выходящие далеко за рамки одного предложения. Для этого сравнивать надо на больших текстах.