



KK
Подробный результат прогона текста в джейсоне можно посмотреть, там же и затестить можно
Size: a a a
KK
BS
BS
SA
SA
V
SA
НК
НК
A
AT
AT
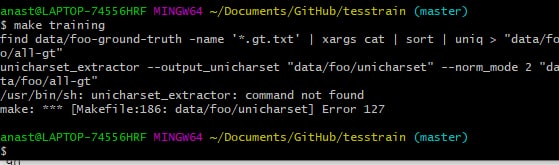
AT
AT

НК
A
The implementation parallelizes Regular Expression matching across lines in a file
по линиям это не как-то ен совсем регулярки сами по себеAP
MK
AP
AK

