



MB
Поэтому в вершине фенвика хранится и такая, "взвешенная" сумма, и обычная.
Этого достаточно для пересчета
Этого достаточно для пересчета
Size: a a a
MB
MB
e
BM
i
i
OO
OO
i
AT
LC_ALL="C" awk -F '[^A-Za-z]+' '{ for(i = 1; i <= NF; ++i) if ($i) ++w[tolower($i)] } END { for(i in w) print w[i], i }' $1 | sort -k1gr,2
(т.е. всё, кроме a-zA-Z — это пробелы, остальное — формирует слова; выводятся две колонки: сколько раз встретилось слово в убывающем порядке и само слово в нижнем регистре)3343241 the
1852717 and
1715705 of
1560152 to
1324244 a
956926 in
933954 i
781286 he
713514 that
690876 was
665710 it
...
AT
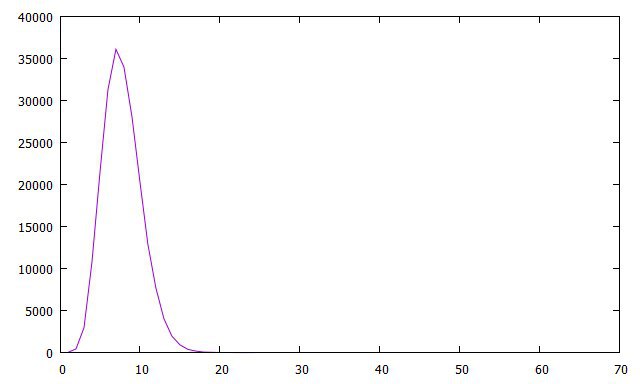
AT
l
LC_ALL="C" awk -F '[^A-Za-z]+' '{ for(i = 1; i <= NF; ++i) if ($i) ++w[tolower($i)] } END { for(i in w) print w[i], i }' $1 | sort -k1gr,2
(т.е. всё, кроме a-zA-Z — это пробелы, остальное — формирует слова; выводятся две колонки: сколько раз встретилось слово в убывающем порядке и само слово в нижнем регистре)3343241 the
1852717 and
1715705 of
1560152 to
1324244 a
956926 in
933954 i
781286 he
713514 that
690876 was
665710 it
...
AT
l
l
AT
AT
AT
