



ВК
Size: a a a
2019 November 11
ВК
Тут и структура многоуровневая и имена узлов повторяются.
2019 November 12
👁
Тут и структура многоуровневая и имена узлов повторяются.
#Если структура не меняется и есть фигурные скобки:
#разделение по customerAction
a <- gregexpr("<customerAction>(.*?)</customerAction>",text)
b <- unlist(regmatches(text,a))
#разделение по фигурным скобкам
c <- gregexpr("\\{(.*?)\\}",b)
d <- unlist(regmatches(b,c))
#удаление скобок
d <- gsub("\\{|\\}","",d)
#таблица
dim(d) <- c(15,length(d)/15)
d <- t(d)
d <- as.data.table(d)
#Если фигурных скобок нету, то, зная структуру, можно выделить все идентификаторы по порядку и далее формировать из них таблицу
a <- gregexpr("<customerAction>(.*?)</customerAction>",text)
b <- unlist(regmatches(text,a))
c1 <- gregexpr("<mindboxId>(.*?)</mindboxId>",b)
d1 <- unlist(regmatches(b,c1))
d1 <- gsub("<mindboxId>|</mindboxId>","",d1)
c2 <- gregexpr("<transactionId>(.*?)</transactionId>",b)
d2 <- unlist(regmatches(b,c2))
d2 <- gsub("<transactionId>|</transactionId>","",d2)
#и так далее
dim(d1) <- c(2,length(d1)/2)
d1 <- t(d1)
d1 <- as.data.table(d1)
dim(d2) <- c(1,length(d2)/1)
d2 <- t(d2)
d2 <- as.data.table(d2)
d <- cbind(d1,d2)ВК
👁
#Если структура не меняется и есть фигурные скобки:
#разделение по customerAction
a <- gregexpr("<customerAction>(.*?)</customerAction>",text)
b <- unlist(regmatches(text,a))
#разделение по фигурным скобкам
c <- gregexpr("\\{(.*?)\\}",b)
d <- unlist(regmatches(b,c))
#удаление скобок
d <- gsub("\\{|\\}","",d)
#таблица
dim(d) <- c(15,length(d)/15)
d <- t(d)
d <- as.data.table(d)
#Если фигурных скобок нету, то, зная структуру, можно выделить все идентификаторы по порядку и далее формировать из них таблицу
a <- gregexpr("<customerAction>(.*?)</customerAction>",text)
b <- unlist(regmatches(text,a))
c1 <- gregexpr("<mindboxId>(.*?)</mindboxId>",b)
d1 <- unlist(regmatches(b,c1))
d1 <- gsub("<mindboxId>|</mindboxId>","",d1)
c2 <- gregexpr("<transactionId>(.*?)</transactionId>",b)
d2 <- unlist(regmatches(b,c2))
d2 <- gsub("<transactionId>|</transactionId>","",d2)
#и так далее
dim(d1) <- c(2,length(d1)/2)
d1 <- t(d1)
d1 <- as.data.table(d1)
dim(d2) <- c(1,length(d2)/1)
d2 <- t(d2)
d2 <- as.data.table(d2)
d <- cbind(d1,d2)Фигурных скобок нет. Это так в описании значения указали.
На b <- unlist(regmatches(text,a)) выдает ошибку:
Error in regmatches(get_answer, a) :
‘x’ и ‘m’ должны иметь одинаковую длину
На b <- unlist(regmatches(text,a)) выдает ошибку:
Error in regmatches(get_answer, a) :
‘x’ и ‘m’ должны иметь одинаковую длину
👁
Фигурных скобок нет. Это так в описании значения указали.
На b <- unlist(regmatches(text,a)) выдает ошибку:
Error in regmatches(get_answer, a) :
‘x’ и ‘m’ должны иметь одинаковую длину
На b <- unlist(regmatches(text,a)) выдает ошибку:
Error in regmatches(get_answer, a) :
‘x’ и ‘m’ должны иметь одинаковую длину
Не знаю почему так. На всякий случай напишу что у text класс character и 1 элемент
PU
а xml2 не зашел?
PU
у меня как-то так на коленке получилось, общая логика вроде как прослеживается
имейте ввиду, я до этого с парсингом xml не сталкивался, так что может быть очень костыльно
имейте ввиду, я до этого с парсингом xml не сталкивался, так что может быть очень костыльно
> library(xml2)
> tmp <- read_xml('~/Загрузки/template.xml')
> sec <- xml_children(xml_children(tmp))
> cast_actions <- xml_find_all(sec, '//customerActions')
> el1 <- xml_children(cast_actions)[[1]]
>
> result <- data.frame(
+ ids = xml_find_first(el1, '//customerAction/ids/mindboxId') %>% xml_text(),
+ transactionId = xml_find_first(el1, '//customerAction/ids/transactionId') %>% xml_text(),
+ systemName = xml_find_first(el1, '//customerAction/actionTemplate/systemName') %>% xml_text())
>
> for (i in seq_len(length(result))) {
+ result[, i] <- gsub('\\{|\\}', '', result[, i])
+ }
>
> result
ids transactionId systemName
1 Идентификатор действия в Майндбокс Внешний идентификатор действия Системное имя шаблона действия в Майндбоксе
ВК
у меня как-то так на коленке получилось, общая логика вроде как прослеживается
имейте ввиду, я до этого с парсингом xml не сталкивался, так что может быть очень костыльно
имейте ввиду, я до этого с парсингом xml не сталкивался, так что может быть очень костыльно
> library(xml2)
> tmp <- read_xml('~/Загрузки/template.xml')
> sec <- xml_children(xml_children(tmp))
> cast_actions <- xml_find_all(sec, '//customerActions')
> el1 <- xml_children(cast_actions)[[1]]
>
> result <- data.frame(
+ ids = xml_find_first(el1, '//customerAction/ids/mindboxId') %>% xml_text(),
+ transactionId = xml_find_first(el1, '//customerAction/ids/transactionId') %>% xml_text(),
+ systemName = xml_find_first(el1, '//customerAction/actionTemplate/systemName') %>% xml_text())
>
> for (i in seq_len(length(result))) {
+ result[, i] <- gsub('\\{|\\}', '', result[, i])
+ }
>
> result
ids transactionId systemName
1 Идентификатор действия в Майндбокс Внешний идентификатор действия Системное имя шаблона действия в Майндбоксе
Так почему-то только одна строка и то частично распарсилась.
PU
эм. потому что код написан для дочерних трех элементов одной строки, а не для всех?
мне кажется, я показал принцип, и он вроде рабочий. расписывать полный парсер у меня нет времени.
мне кажется, я показал принцип, и он вроде рабочий. расписывать полный парсер у меня нет времени.
👁
👁
Не знаю почему так. На всякий случай напишу что у text класс character и 1 элемент
нашел функцию для чтения файла в такой формат
library(readr)
text <- read_file("template.xml")
PU
PU
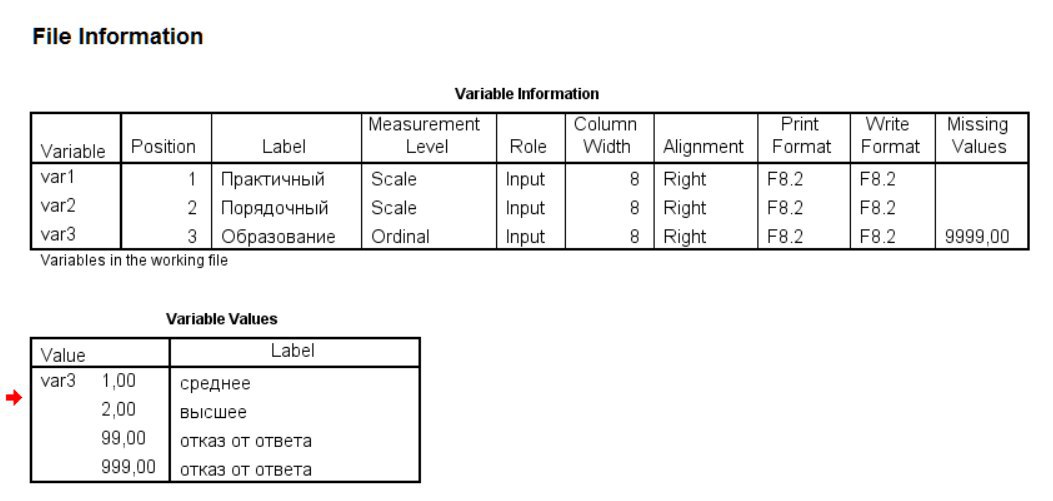
у него вот такая структура
ГД
кстати, раз уж речь пошла про парсинг
я правильно понимаю, что haven вот такой файл не очень хорошо жрет и его лучше импортировать через foreign::read.spss?
я правильно понимаю, что haven вот такой файл не очень хорошо жрет и его лучше импортировать через foreign::read.spss?
А в чем проблема? У меня нормально читает
PU
в табличку хреново конвертируется
> library(haven)
> path <- './data/spss_example.sav'
> spss_data <- read_sav(path)
> spss_data
Ошибка в `levels<-`(`*tmp*`, value = as.character(levels)) :
factor level [4] is duplicated
PU
приходится вот так вот извращаться
> spss_data_df <- as.data.frame(spss_data, stringAsFactor = FALSE)
> spss_data_df
var1 var2 var3
1 3 4 1
2 4 5 NA
3 3 5 99
4 3 5 1
5 4 4 4
6 3 5 999
PU
ну и в целом у haven, кажется, меньше настроек для импорта, чем у foreign
поэтому и вопрос - чем же он так хорош (ну, кроме того, что haven читает еще и стату, и пишет и спсс, и стату)
поэтому и вопрос - чем же он так хорош (ну, кроме того, что haven читает еще и стату, и пишет и спсс, и стату)
ГД
субъективно haven побыстрее и строковые перемененные с большим количеством знаков в спссных файлах не разбивает на несколько столбцов.
ГД
в табличку хреново конвертируется
> library(haven)
> path <- './data/spss_example.sav'
> spss_data <- read_sav(path)
> spss_data
Ошибка в `levels<-`(`*tmp*`, value = as.character(levels)) :
factor level [4] is duplicated
Странно, у меня не пытается в фактор переделать
ГД
haven версии 2.2.0
PU
хм. у меня haven_2.1.1. сейчас попробую обновить