PU
и ведь что самое смешное, оно и работает, и синтаксически корректно
Size: a a a
PU
PU
OB
PU
VN
df[df['Name']=='Ron Wealsey',]['Name'] <- 'Ron Weasley'
PU
got_chars_bar[['female']] <- got_chars_bar[['n']] - got_chars_bar[['male']]
ЕТ
ЕТ
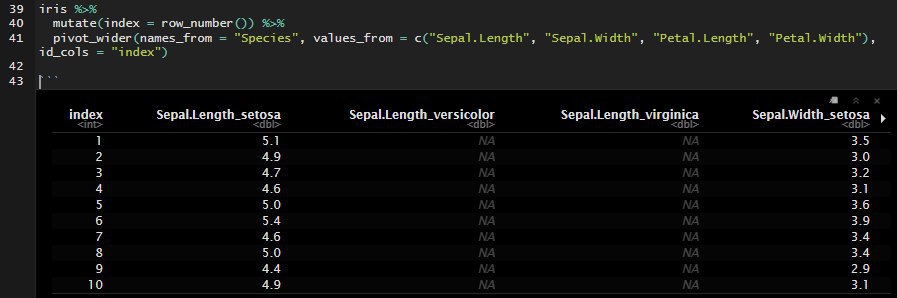
iris %>%
mutate(index = row_number()) %>%
pivot_wider(names_from = "Species", values_from = c("Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"), id_cols = "index")
ГД
ЕТ
ГД
ЕТ
ЕТ
ЕТ
ГД
ЕТ