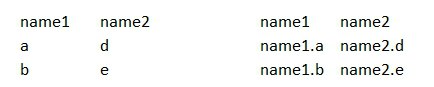a
мне бы в идеале название/авторов/теги/рефренсы/аннотации
Мы недавно выкачивали из crosref, там есть API. И у нас есть какой-то 9Г дамп.
Size: a a a
a
R
А
AM
rsthemes (он упоминается в посте Алексея) и выполните rsthemes::install_rsthemes(include_base16 = TRUE). появится куча тем, большинство из которых удовлетворяет таким условиям. да и светлые темы там очень даже ничегоhttps://github.com/gadenbuie/rsthemesPD
rsthemes (он упоминается в посте Алексея) и выполните rsthemes::install_rsthemes(include_base16 = TRUE). появится куча тем, большинство из которых удовлетворяет таким условиям. да и светлые темы там очень даже ничегоhttps://github.com/gadenbuie/rsthemesВ
a
library(tidyverse)
mtcars %>%
mutate(id = 1:n()) %>%
pivot_longer(names_to = "cols", values_to = "values", mpg:carb) %>%
mutate(new_values = str_c(cols, ".", values)) %>%
select(-values) %>%
pivot_wider(names_from = cols, values_from = new_values)
YS
PU
a
PU
a
library(tidyverse)
map_dfr(1:nrow(mtcars), function(i){
str_c( colnames(mtcars), ".", mtcars[i,]) %>%
as_tibble_row(.name_repair = "unique")
}) ->
df
colnames(df) <- colnames(mtcars)
df
В
m
caret под Windows?doParallel ещё doSNOW, но все они дают небольшое ускорение, +10-15%.m
caret как набор всяких ML-библиотек ещё оправдан? Может, что-то лучше уже есть?AS
m
JS
caret под Windows?doParallel ещё doSNOW, но все они дают небольшое ускорение, +10-15%.AS