



IS
Угу - много вы знаете оптимических приборов способных ночью снять спектр звезды?. Ситемы навигации по звездам как раз работают по созвездиям. зная в моменте координаты которых - можно определить свое местоположение
Size: a a a
IS
IS
IS
IS
E
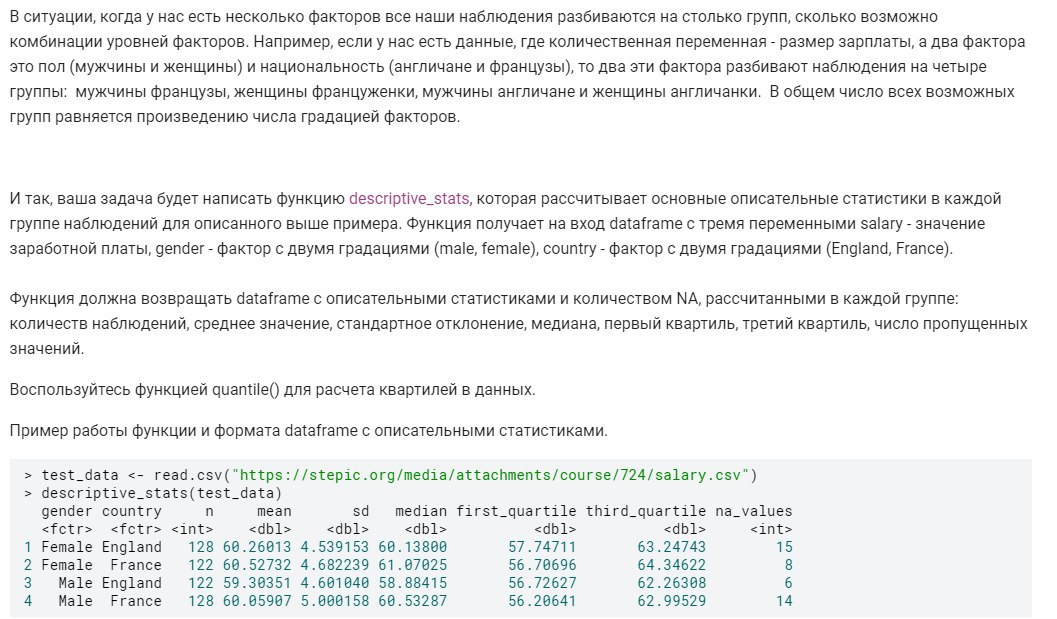
test_data <- read.csv("https://stepic.org/media/attachments/course/724/salary.csv")
descriptive_stats <- function (dataset){
var<-names(which(sapply(test_data, is.factor)))
new_dataset<-group_by(dataset,{{var}})%>%
summarise (n=n(),mean=mean(na.rm=T),
sd=sd(na.rm = T), median=median(na.rm = T),
first_quartile=quantile(0,25, na.rm = T),
third_quartile=quantile( 0,75, na.rm = T),
na_values=sum(is.na()))
return(new_dataset)
}
descriptive_stats(test_data)IS
test_data <- read.csv("https://stepic.org/media/attachments/course/724/salary.csv")
descriptive_stats <- function (dataset){
var<-names(which(sapply(test_data, is.factor)))
new_dataset<-group_by(dataset,{{var}})%>%
summarise (n=n(),mean=mean(na.rm=T),
sd=sd(na.rm = T), median=median(na.rm = T),
first_quartile=quantile(0,25, na.rm = T),
third_quartile=quantile( 0,75, na.rm = T),
na_values=sum(is.na()))
return(new_dataset)
}
descriptive_stats(test_data);
;
a
a
test_data <- read.csv("https://stepic.org/media/attachments/course/724/salary.csv")
descriptive_stats <- function (dataset){
var<-names(which(sapply(test_data, is.factor)))
new_dataset<-group_by(dataset,{{var}})%>%
summarise (n=n(),mean=mean(na.rm=T),
sd=sd(na.rm = T), median=median(na.rm = T),
first_quartile=quantile(0,25, na.rm = T),
third_quartile=quantile( 0,75, na.rm = T),
na_values=sum(is.na()))
return(new_dataset)
}
descriptive_stats(test_data)read.csv() по умолчанию векторы не превращаются больше в факторы. Так что вам придется добавить stringsAsFactors = TRUE в read.csv(). Но и еще много чего исправить, конечноЕТ
a
IS
test_data <- read.csv("https://stepic.org/media/attachments/course/724/salary.csv")
descriptive_stats <- function (dataset){
var<-names(which(sapply(test_data, is.factor)))
new_dataset<-group_by(dataset,{{var}})%>%
summarise (n=n(),mean=mean(na.rm=T),
sd=sd(na.rm = T), median=median(na.rm = T),
first_quartile=quantile(0,25, na.rm = T),
third_quartile=quantile( 0,75, na.rm = T),
na_values=sum(is.na()))
return(new_dataset)
}
descriptive_stats(test_data)E
test_data <- read.csv("https://stepic.org/media/attachments/course/724/salary.csv")
test_data %>%
group_by(gender, country) %>%
summarise (n=n(), mean=mean(salary,na.rm=T),
sd=sd(salary,na.rm = T), median=median(salary,na.rm = T),
first_quartile=quantile(salary, 0,25, na.rm = T),
third_quartile=quantile(salary, 0,75, na.rm = T),
na_values=sum(is.na(salary)))ГД
options(stringsAsFactors = FALSE)E
<chr> must be length 500 (the number of rows) or one, not 2"E
test_data <- read.csv("https://stepic.org/media/attachments/course/724/salary.csv", stringsAsFactors = TRUE)
descriptive_stats <- function (dataset){
dataset_num<-select_if(dataset, is.numeric)
factor_vars <-names(which(sapply(dataset, is.factor)))
dataset %>%
group_by({{factor_vars}})%>%
summarise (n=n(),mean=mean(dataset_num,na.rm=T),
sd=sd(dataset_num,na.rm = T), median=median(dataset_num,a.rm = T),
first_quartile=quantile(dataset_num,0,25, na.rm = T),
third_quartile=quantile(dataset_num, 0,75, na.rm = T),
na_values=sum(is.na(dataset_num)))
return(dataset)
}
descriptive_stats(test_data)E
test_data <- read.csv("https://stepic.org/media/attachments/course/724/salary.csv")
descriptive_stats <- function (dataset){
var<-names(which(sapply(test_data, is.factor)))
new_dataset<-group_by(dataset,{{var}})%>%
summarise (n=n(),mean=mean(na.rm=T),
sd=sd(na.rm = T), median=median(na.rm = T),
first_quartile=quantile(0,25, na.rm = T),
third_quartile=quantile( 0,75, na.rm = T),
na_values=sum(is.na()))
return(new_dataset)
}
descriptive_stats(test_data)IS