ЕТ
Лучшее решение никогда на Винде10 не использовать в пути проекта кириллицу
Угу... Я уже перепилил всё. Но очень загадочно, ПОЧЕМУ так. Каков механизм такого бага.
Size: a a a
ЕТ
AK
PU
library(data.table)
dt1 <- data.table(
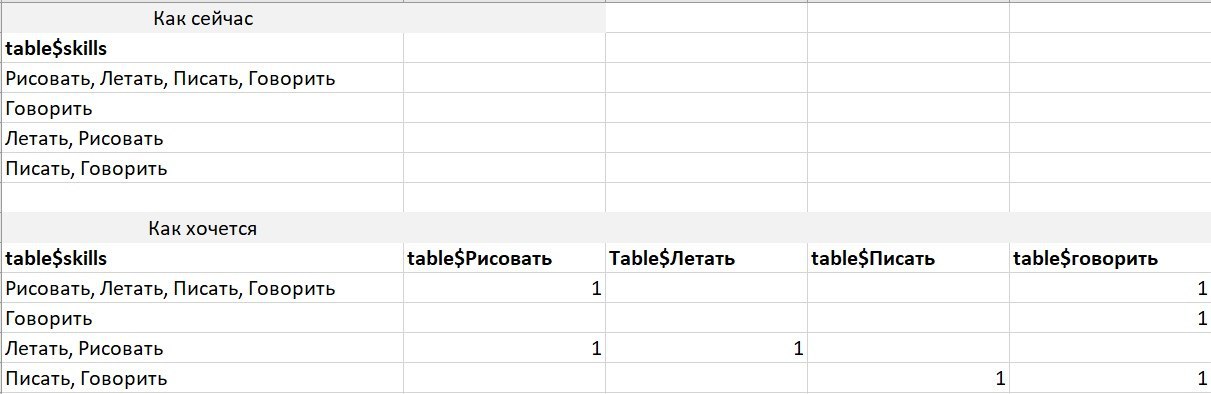
var1 = c('читать, рисовать', 'читать', 'рисовать')
)
dt1[, index := 1:.N]
dt1_long <- dt1[, list(skill = unlist(strsplit(var1, ', '))), by = index]
dt1_wide <- dcast(dt1_long, index ~ skill, fun.aggregate = length, fill = 0)
dt1 <- merge(dt1, dt1_wide, by = 'index', all.x = TRUE)
AK
library(data.table)
dt1 <- data.table(
var1 = c('читать, рисовать', 'читать', 'рисовать')
)
dt1[, index := 1:.N]
dt1_long <- dt1[, list(skill = unlist(strsplit(var1, ', '))), by = index]
dt1_wide <- dcast(dt1_long, index ~ skill, fun.aggregate = length, fill = 0)
dt1 <- merge(dt1, dt1_wide, by = 'index', all.x = TRUE)
PU
AK
PD
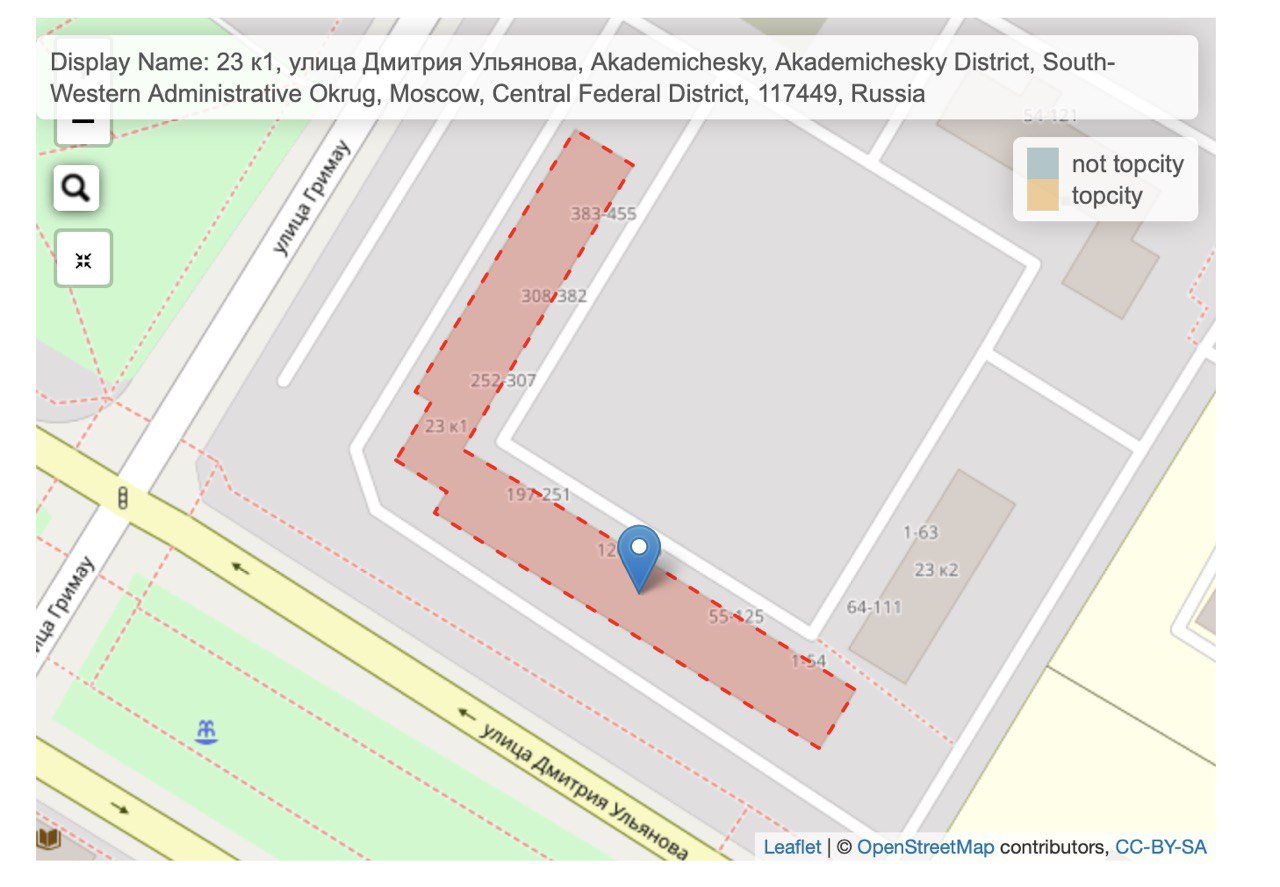
display name.PD
IT
АК
АК
E
pairwise.wilcox.test(df$Calories, df$Category, p.adjust.method = "BH", exact=F, correct=F). Этот тест показывает между какими именно группами есть статистическая разница в калорийности. PD
PD
leaflet.extras есть функция “addReverseSearchOSM”. Не знаю, как я ее сразу не заметил…АК
А[
pairwise.wilcox.test(df$Calories, df$Category, p.adjust.method = "BH", exact=F, correct=F). Этот тест показывает между какими именно группами есть статистическая разница в калорийности. E
БА