



АК
Данные агрегированы, в результате их в дашборд отдаётся не много (не более тысячи строк). Само приложение рядом. Интересует именно быстродействие БД и возможность выполнять множество параллельных запросов с агрегацией без потери скорости.
Size: a a a
АК
JS
JS
АК
JS
JS
AS
AS
JS
АК
JS
JS
JS
ЭА
JS
ЭА
JS
AS
AS
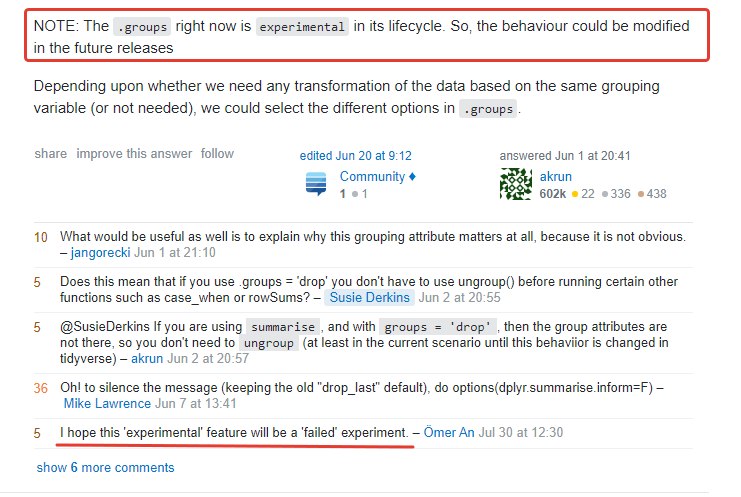
dplyr: "summarise() ungrouping output (override with .groups argument)"AS