St
Dm Kb
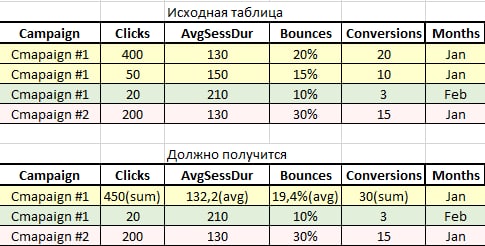
просто убрать столбец:
iris_grp <- group_by(iris, Species)
bind_cols(
summarise(iris_grp, across(1:2, sum, .names = "{.col}_sum")),
summarise(iris_grp, across(3:4, mean, .names = "{.col}_mean"))[, -1]
)
iris_grp <- group_by(iris, Species)
bind_cols(
summarise(iris_grp, across(1:2, sum, .names = "{.col}_sum")),
summarise(iris_grp, across(3:4, mean, .names = "{.col}_mean"))[, -1]
)
Подскажите, можно ли модифицировать этот код, чтобы схлопнуть строки для одной кампании с учетом значений в другом столбце, в конкретном случае - месяце.