ЕК
Подскажите, пожалуйста, я хочу:
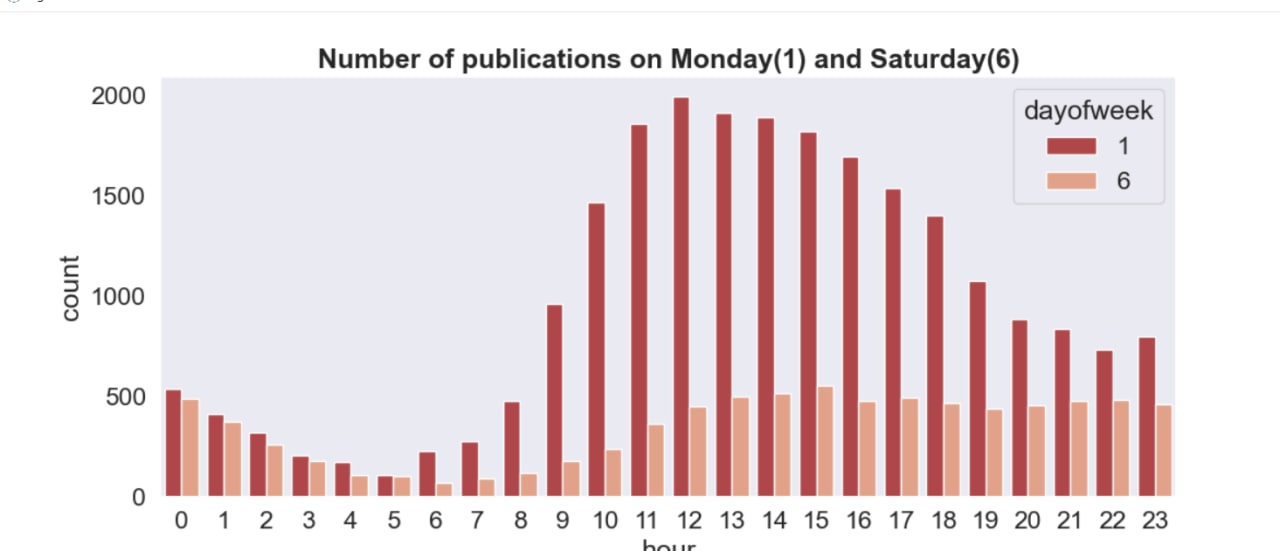
Проверить утверждение, что по субботам авторы пишут в основном днём, а по понедельникам — в основном вечером
И визуализировать это в виде диаграммы, где X - часы, Y - количество статей (пример на фото)
Что у меня есть:
Датасет, в котором присутствует столбец
Подскажите, пожалуйста, как мне это сделать с помощью ggplot
Проверить утверждение, что по субботам авторы пишут в основном днём, а по понедельникам — в основном вечером
И визуализировать это в виде диаграммы, где X - часы, Y - количество статей (пример на фото)
Что у меня есть:
Датасет, в котором присутствует столбец
published(дата и время публикации), где хранятся данные в виде строк в таком формате: 2008-01-01 18:19:00Есть столбец
domain, где название сайтов, у меня их 2 всегоПодскажите, пожалуйста, как мне это сделать с помощью ggplot