



A
Size: a a a
2020 May 26
МС
и емнип формально такие странички не добавляют depth - он же по-факту не идет туда. просто как припадочный волчком по клетке бегает с воплями "выпустите меня, выпустите меня!"
😂, про волчка - до слез....
я бы такое через базу делал. Тем более, когда счет на миллионы идет
я бы такое через базу делал. Тем более, когда счет на миллионы идет
2020 May 27
AV
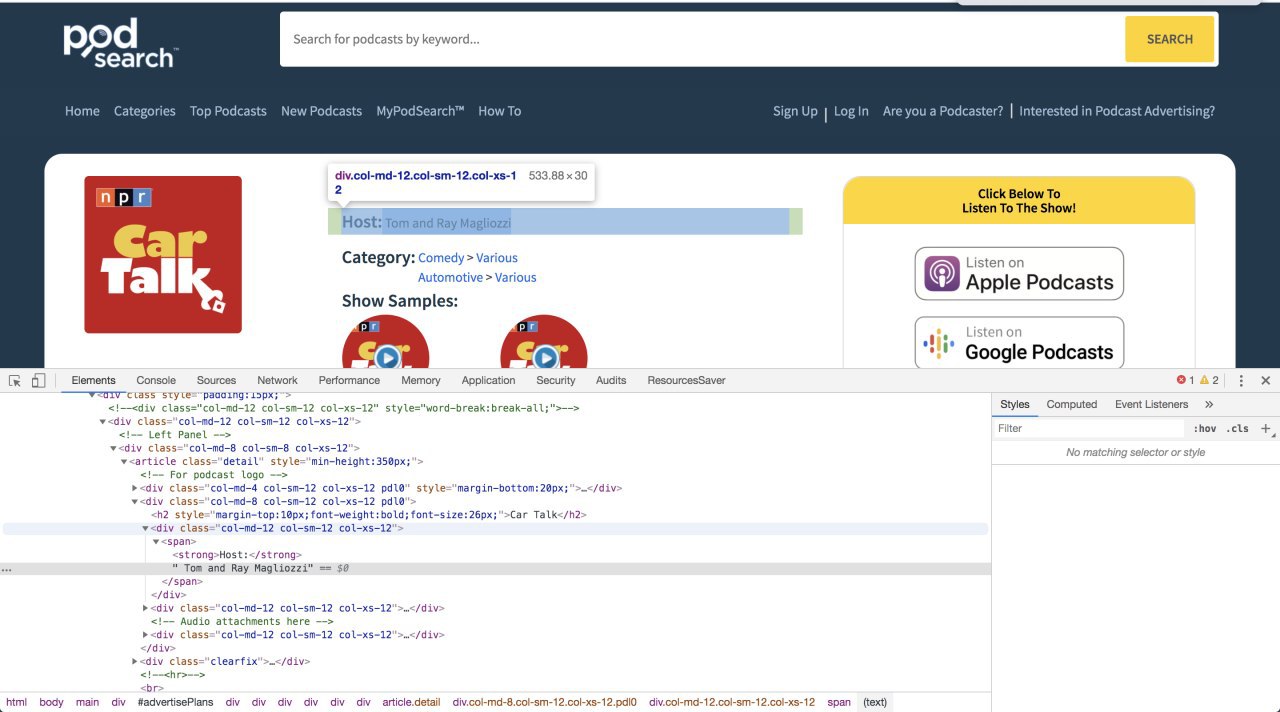
Просьба подтолкнуть на мысль как проще всего можно извлечь " Tom and Ray Magliozzi" (использую BeautifulSoup)
При таком селекторе получается множество лишних вариантов по которым нужно впоследствии итерировать чтобы выбрать лучший. Неужели это и есть самый простой способ?
page_soup.findAll('div', {"class":"col-md-12 col-sm-12 col-xs-12"})
Ссылка: podsearch.com/listing/car-talk.html
При таком селекторе получается множество лишних вариантов по которым нужно впоследствии итерировать чтобы выбрать лучший. Неужели это и есть самый простой способ?
page_soup.findAll('div', {"class":"col-md-12 col-sm-12 col-xs-12"})
Ссылка: podsearch.com/listing/car-talk.html
AV
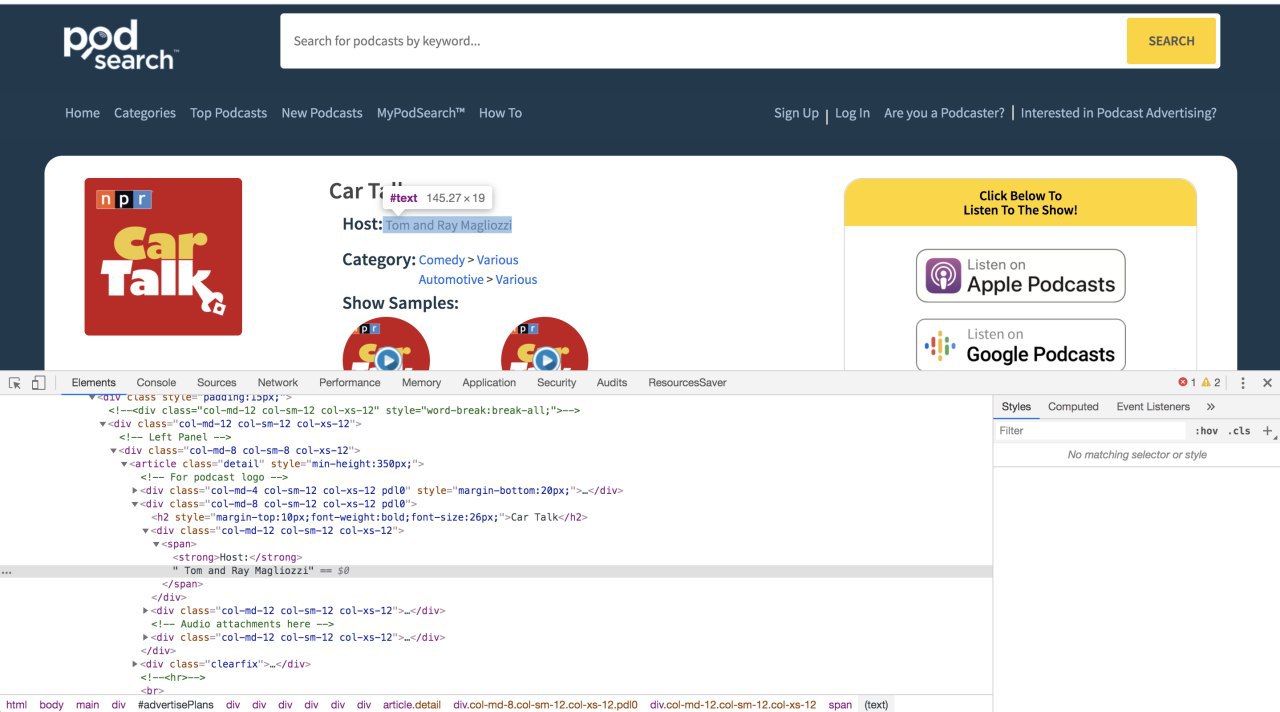
s
Andrei Volkau
/html/body/main/div/div/div/div/div/div/div/div[1]/article/div[2]/div[1]/span/following-sibling::text()
s
я бы xpath применял бы)
только не знаю как его хэндлить в бс4 но наверняка можно
только не знаю как его хэндлить в бс4 но наверняка можно
AV
я бы xpath применял бы)
только не знаю как его хэндлить в бс4 но наверняка можно
только не знаю как его хэндлить в бс4 но наверняка можно
Тоже пока не знаю. Надеюсь можно. Спасибо большое, сейчас попробую!
МС
Andrei Volkau
Просьба подтолкнуть на мысль как проще всего можно извлечь " Tom and Ray Magliozzi" (использую BeautifulSoup)
При таком селекторе получается множество лишних вариантов по которым нужно впоследствии итерировать чтобы выбрать лучший. Неужели это и есть самый простой способ?
page_soup.findAll('div', {"class":"col-md-12 col-sm-12 col-xs-12"})
Ссылка: podsearch.com/listing/car-talk.html
При таком селекторе получается множество лишних вариантов по которым нужно впоследствии итерировать чтобы выбрать лучший. Неужели это и есть самый простой способ?
page_soup.findAll('div', {"class":"col-md-12 col-sm-12 col-xs-12"})
Ссылка: podsearch.com/listing/car-talk.html
//strong[contains(text(), "Host:")]/../text()
AV
//strong[contains(text(), "Host:")]/../text()
Это через xpath я так понимаю?
МС
Andrei Volkau
Это через xpath я так понимаю?
да
МС

s
//strong[contains(text(), "Host:")]/../text()
жиир)
пошел читать книжку по xpath
пошел читать книжку по xpath
МС
а, не, ща найду bs+xpath
МС
не, не найду, там как то при инициализации, вроде, надо настроить.
я просто BS никогда не использовал :)
я просто BS никогда не использовал :)
AV
В любом случае, спасибо большое за xpath
Буду пробывать bs4 c xpath подружить!
Буду пробывать bs4 c xpath подружить!