



К
немного не по теме, но посоветуйте какую-нибудь либу для геокодинга(есть один файл с полигонами и названиями, и второй с координатами, нужно найти какая координата в каком полигоне)
Size: a a a
К
Pu
EB
К
EB
EB
EB
🎱
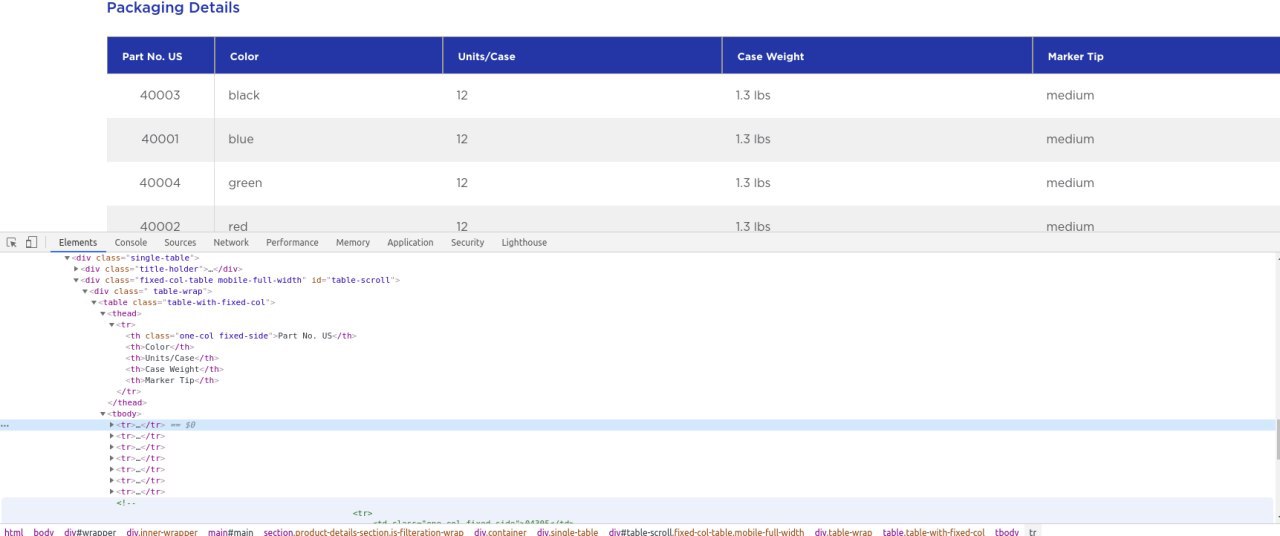
table_results = [
'40003': {
'color': 'black',
'units/case': 12,
'case_weight': '1.3lbs',
'marker_tip': 'medium',
},
'40001': {
'color': 'blue',
'units/case': 12,
'case_weight': '1.3lbs',
'marker_tip': 'medium',
},
....
]
AB
table_results = [
'40003': {
'color': 'black',
'units/case': 12,
'case_weight': '1.3lbs',
'marker_tip': 'medium',
},
'40001': {
'color': 'blue',
'units/case': 12,
'case_weight': '1.3lbs',
'marker_tip': 'medium',
},
....
]
AB
t
AB
