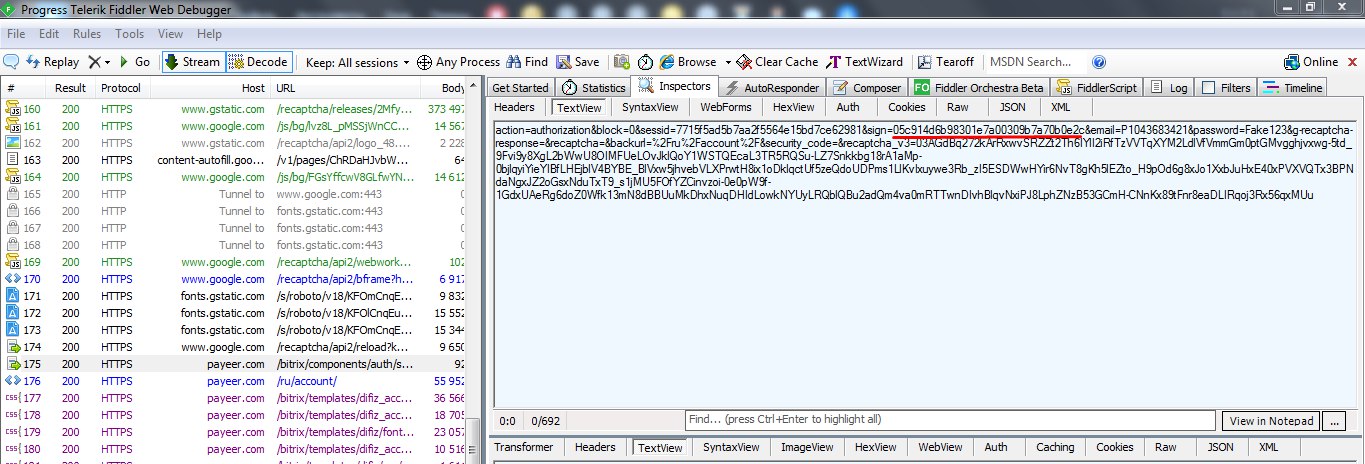
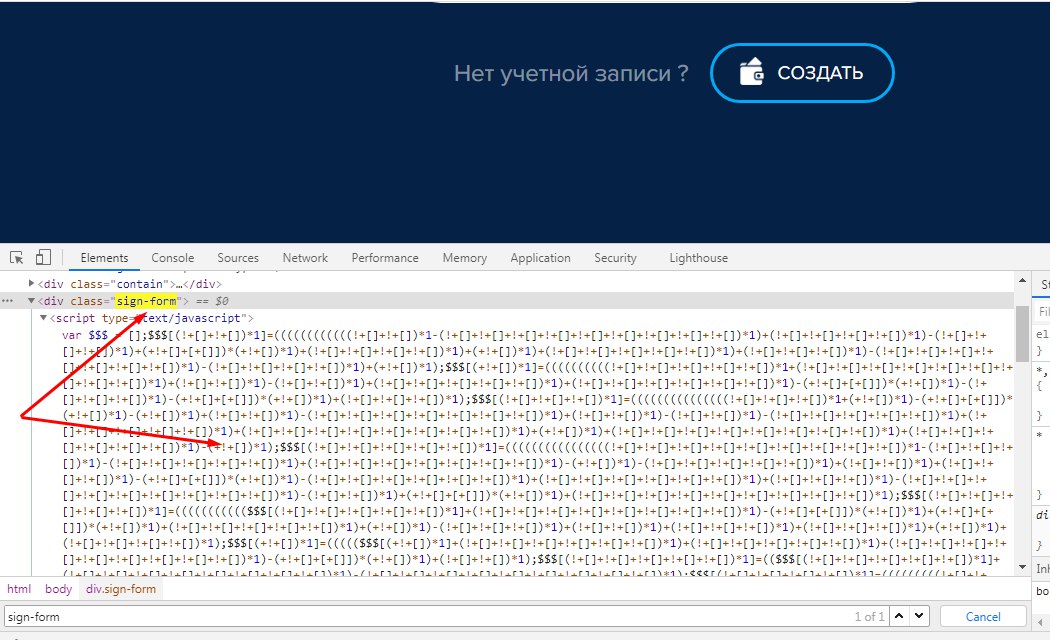
Последний вопрос от дилетанта: достаточно ли будет сохранить полученную GET'ом HTML-ку на s3, чтобы потом ее дорендерить в случае необходимости без повтороного GET запроса за этой же html кой?
Скорее нет чем да, но если прямо так задача стоит то можно попробовать
Всё ещё непонятно в чем там проблема, ты бы сам посмотрел для начала
я сам смотрел, пытался залогиниться, но скажем так со сложными сайтами у меня проблемы с авторизацией и попросил прошареного чела мне помочь, он мне это и пояснил
я сам смотрел, пытался залогиниться, но скажем так со сложными сайтами у меня проблемы с авторизацией и попросил прошареного чела мне помочь, он мне это и пояснил