ну да. О чем я и писал выше. там latency не в самом свитче, а в буферах выше. Если выключить LRO/TCO на картах, то можно сократить прилично. Плюс сам vmk + vswitch
но по прежнему не понимаю, как это влияет на суть вопроса - при целевой latency в районе 1ms (потому что всем наплевать на 4K 100% Read, а важнее 32K 60/40) то 70us не играет ровно не никакой роли
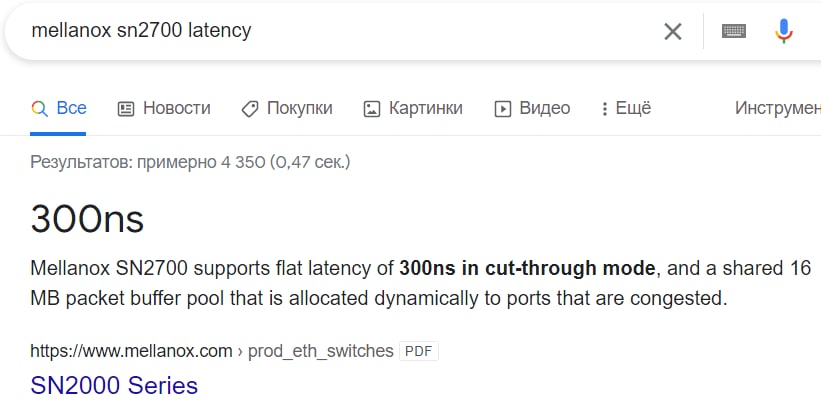
ну то есть если если читать по сети второй раз блок в 16мб он приедет с задержкой в 70ns, а если в первый раз то с задержкой в 330ns, что в 10 раз больше чем nvme и даже в 3 раза больше чем nvme 100ns