А тут тоже есть сложности :) 1. Не ясно, какие слова считаются стоп-словами, чтобы не участвовать в рассчете. 2. Не ясна значимость тех или иных полей (20 вхождений в анкоры исходящих != 20 вхождениям в текст или пассажи (хотя пассажи - это больше про Яндекс)). 3. Не учитывается весь корпус документов.
А тут тоже есть сложности :) 1. Не ясно, какие слова считаются стоп-словами, чтобы не участвовать в рассчете. 2. Не ясна значимость тех или иных полей (20 вхождений в анкоры исходящих != 20 вхождениям в текст или пассажи (хотя пассажи - это больше про Яндекс)). 3. Не учитывается весь корпус документов.
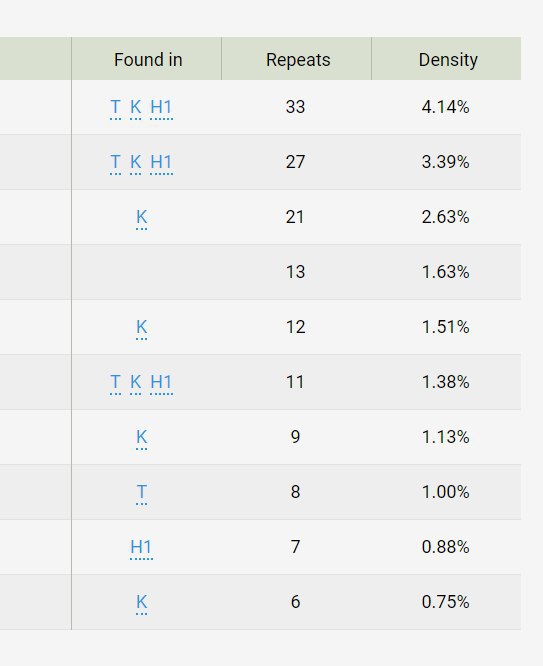
Короче, пользоваться только tf - так себе история
ну так, я про тоже, я на него особо не смотрел, но текущее распределение ключей адекватно вышло
хотя 1 теперь поправить надо, через неделю посмотрю, но это тоже не лабораторные условия, слишком много правок катится постоянно
Я кстати почему спрашивал. Не поверишь, я вчера решил похожий недоэксперимент запустить. Правда больше под Яндекс. И гипотезы другие, но тоже про размер, расположение и вхождения )
не, просто на всех сайтах у всех страниц одинаковые тексты по структуре, разный смысл, но частота и место употребления основного ключа везде +- одинакова, правило русского языка, чтобы смысл повествования не терялся
Я кстати почему спрашивал. Не поверишь, я вчера решил похожий недоэксперимент запустить. Правда больше под Яндекс. И гипотезы другие, но тоже про размер, расположение и вхождения )