JF
@pankrashkin правильно
Size: a a a
JF
JF
А
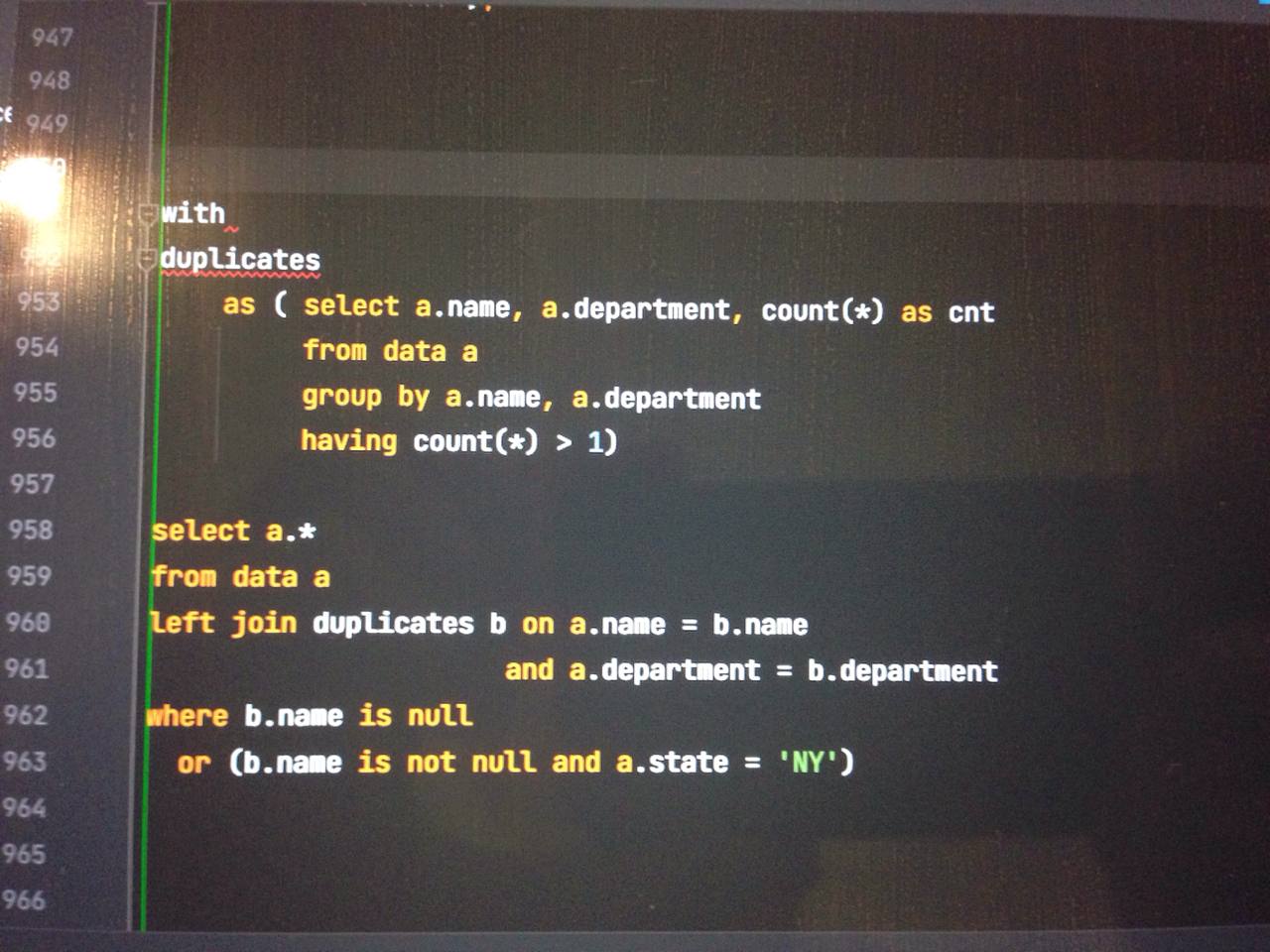
val cols = spark.read.table(tableName).columns.map(x => col(x))
val res = df.select(cols:_*)
.withColumn("rn", row_number over Window.partitionBy("name", "department").orderBy("name"))
.filter("rn == 1")JF
IS
JF
JF
АА
ЕГ
ЕГ
GP
M
ПФ
ПФ
M
ПФ
M
M