YB
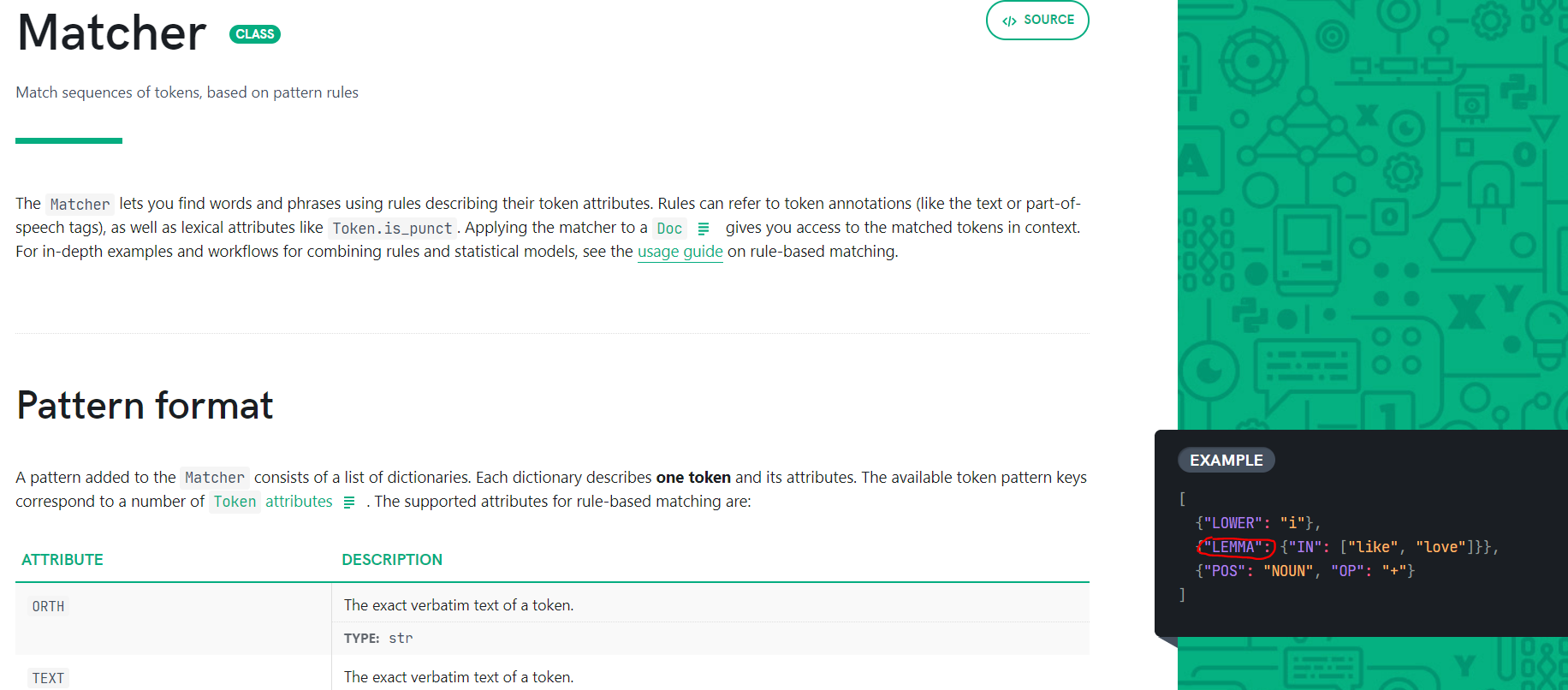
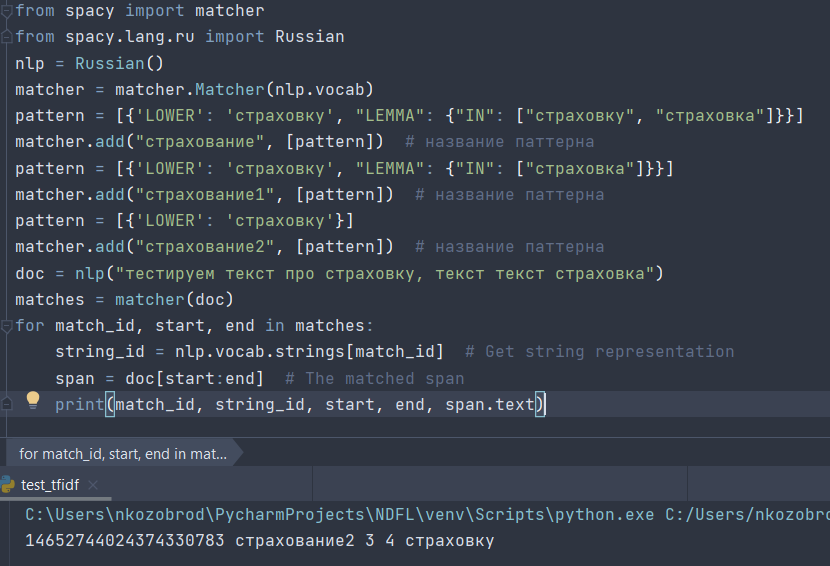
Всем привет! у меня возник вопрос по поводу spacy matcher. Я не понимаю, можно ли его как-то использовать, чтобы он искал начальную форму слова? Я нашел в документации параметр lemma, но опять же, судя по документации - это что-то другое. Конечно есть вариант сначала весь текст прогонять через Pymorphy, а уж потом искать, но может есть вариант без костылей? В целом задача такая: есть список фраз подвязанных к тематикам, есть транскрибция разговоров - хочу помечать то, что нашлось, а то что не нашлось кластеризировать и формировать новые тематики. P.s. На картинке кусок документации spacy, где like и love вроде как леммы слова i. Я видимо не так понимаю смысл слова Lemma и это не начальная форма, а что-то другое?
Lemma -- это то, что надо, но не забудь сначала прогнать текст через морфо-синтаксический анализ, чтобы лемма заполнилась данными.