AB
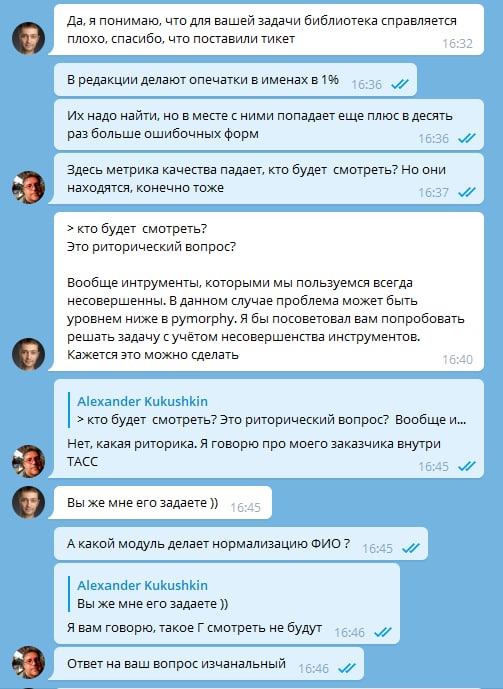
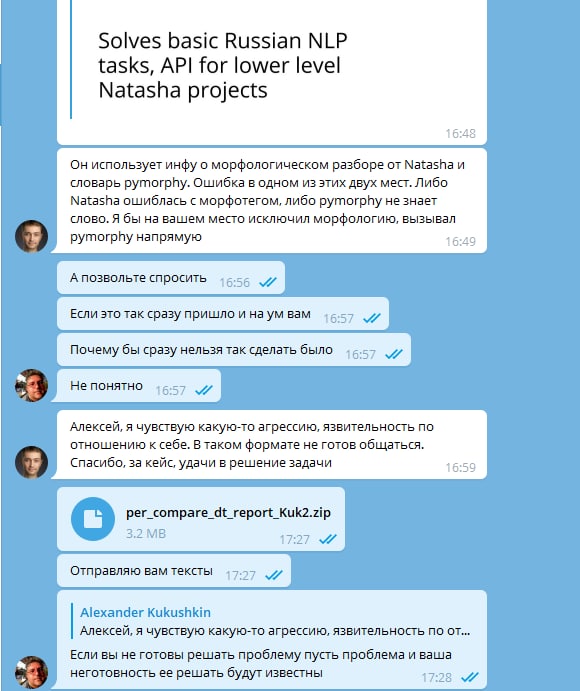
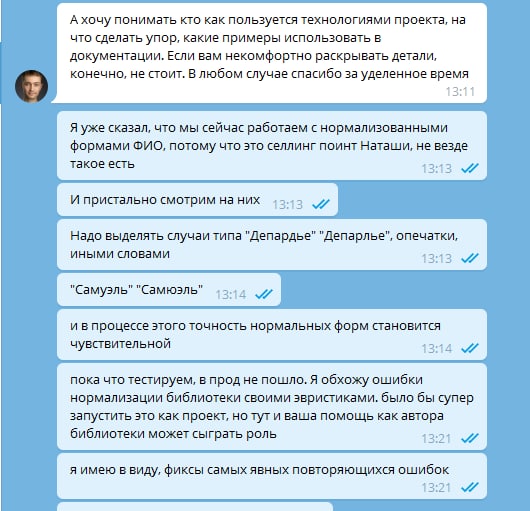
@alexkuk , автор Natasha Отказался общаться со мной, после обсуждения ошибок в работе библиотеки. Было заведено issue на githab проекта: https://github.com/natasha/natasha/issues/93 Проблема состоит в том, что библиотека создает весьма значительно количество неправильных normal форм ФИО, о чем было подробно рассказано Автору с приложением текстов, где эта проблема встречается. На нашем корпусе текстов мы ее видим довольно часто. А учитывая, что именно нормальные формы у нас используются для анализа, мы ищем опечатки в ФИО (отличается один символ). В итоге, в корпусе текстов, где присутствуют как минимум два одних и тех же ФИО, и их нормализованные формы отличаются на 1 символ, ложно-положительных срабатываний более 99%. Это те случаи, когда опечатки не было, а была неправильная нормализованная форма. Эти 99% процентов, конечно, не являются универсальной метрикой качества Natsha NER normal. Как указано в issue в ходе тестирования мы выявили, что если в тексте есть как минимум два раза встречается ФИО, и есть отличие на 1 символ, то 99% и более - это ошибка библиотеки. В связи в этим, а также тем фактом, что Автор были выслано для анализа 3200 текстов, содержащих 5631 ошибку - в качестве базы для анализа этого бага (несовершества), весьма странно выглядит то, что он отказался обсуждать решение, сославшись на несовершенство компонентов.