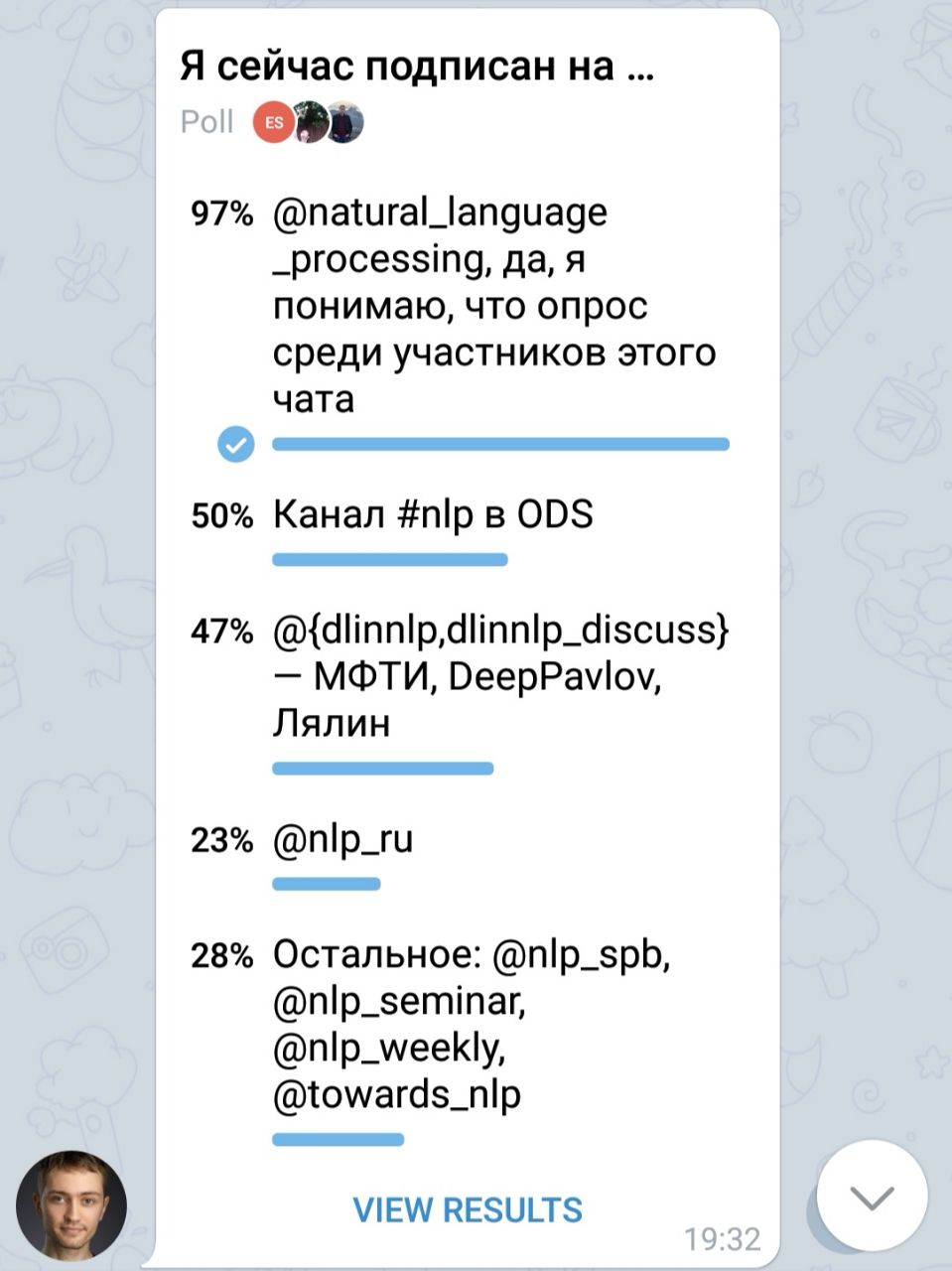
Любопытно, что обычный человек и 1Гб не прочитывает за десятилетия, а шарит в бою так сказать.
У человека особенность, обычно в течение жизни он движется от низкоуровневых источников инфы к высокоуровневым (в широком смысле). С букваря к простым текстам, от простых текстов к средним и оттуда к сложным / специализированным. Машины же обучают на всех текстах вперемешку, насколько я понимаю.