SS
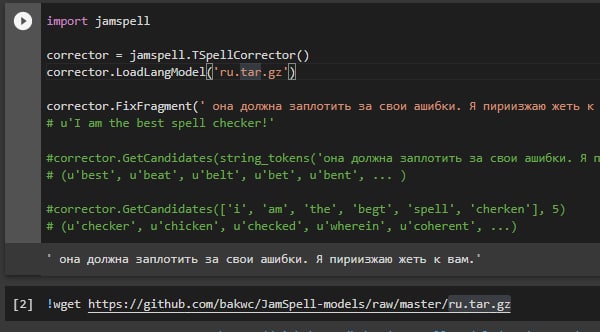
Привет! Я недавно познакомилась с Наташей, и сейчас пытаюсь понять, как можно выделить из предложения связанные друг с другом словосочетания. Понятно, что они хранятся в doc.syntax, но как получить оттуда списки или какой-то аналог subtree из spacy я решительно не понимаю. Вы не могли бы подсказать?