



АГ
Size: a a a
2021 April 17
ch
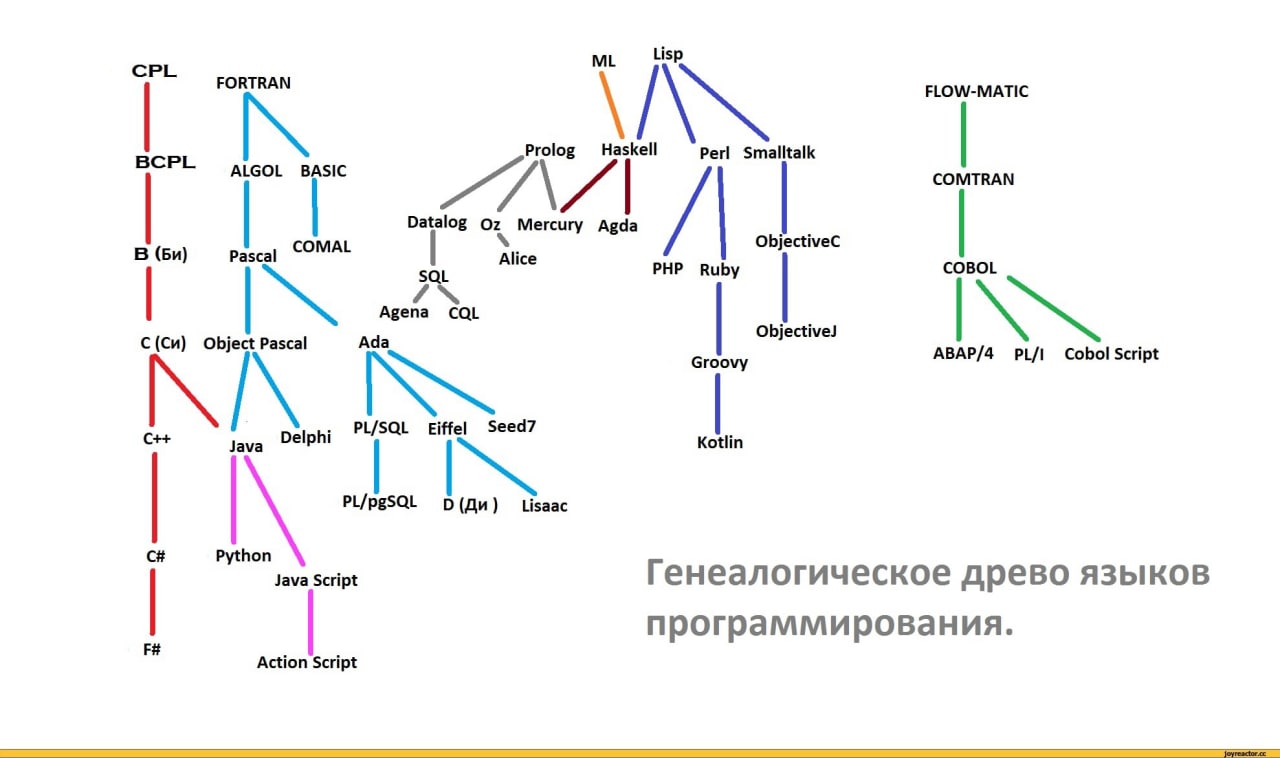
какой то бред

AN
Все эти деревья бессмысленны с конца 90-х. Все современные языки - продукт свального греха всех со всеми
АХ
Цена запуска в статьей указана $75000 или миллионов 6. Половина бюджета
AN
Просто я знаю, что даже у мизерного чибиса только разработка по 100 мульенов. И это без запуска. И это спутничОк на 5-7 кг
АХ
Это заметно более типовая штука. И потому должна быть куда дешевле. Интереснее как они собираются отбивать эти миллионы
ch
стоимость под 100 милионов потому что даже если у тебя спутник стоит пару тысячь его надо прогнать через гору испытаний которые нифига не бесплатные
ch
а пока ты эти испытания не пройдешь, никто и никогда твой спутник на ракету не поставит
AN
Да, специальная электроника, военная приемка и т. д.
AN
Это я к тому, что сумма в заголовке ни о чем
IP
Бред полнейший - непонятно, что значит ребро между двумя языками
KD
Не так давно поднимал тему миграции схемы данных в NoSQL хранилищах.
Потратив время, обдумав это всё, поизучая вопросы — не удалось придти к какому-то единому мнению о том, как это стоит реализовывать.
Снова хочется послушать мнения людей более сведущих в теме.
Что имеем:
• Коллекции NoSQL документов отображающих какие-то данные
• Переодическое изменение схемы этих данных, с которыми нужно как-то справляться
Если SQL из коробки содержит средства для работы с миграциями, то в NoSQL всё скудно и грустно.
Варианты которые я вижу (и на которую меня тут натолкнули):
1) Забивать на миграцию и работать всегда с теми данными, которые имеются, а так же доп. логика на все кейсы, когда этих данных нет (дефолтные значения, маппинг, проброс ошибок).
Например, нужно добавить новое поле в класс, а в старых документах его нет => при чтении, если в документе отсутствует поле, добавляем некое дефолтное значение при создании класса.
Нужно удалить поле — оно просто игнорируется.
2) Сделать общую логику миграции на клиенте. Хранить каждый документ с номером текущей версии и мигрировать до актуальной при чтении документа при необходимости.
Например, нужно добавить поле.
При чтении видим, что версия документа меньше текущей на устройстве.
Производим миграцию документа до текущей версии, т.е. добавляем новое поле.
Отправляем новую версию документа на сервер для перезаписи старого.
Работаем дальше.
У обоих подходов видятся плюсы и минусы.
Первый вариант очевидно проще.
Второй кажется оверхедом, однако в какой-то мере выглядит как тот же первый, но более структурированый, что плюс.
Гуглеж тоже не упростил задачу.
В общем.
Для меня это первый реальный опыт работы с NoSQL хранилищем как основной БД, поэтому хочется узнать как это обычно делают и как принято, чтобы не нагородить хероты сразу же.
Что скажете?
Потратив время, обдумав это всё, поизучая вопросы — не удалось придти к какому-то единому мнению о том, как это стоит реализовывать.
Снова хочется послушать мнения людей более сведущих в теме.
Что имеем:
• Коллекции NoSQL документов отображающих какие-то данные
• Переодическое изменение схемы этих данных, с которыми нужно как-то справляться
Если SQL из коробки содержит средства для работы с миграциями, то в NoSQL всё скудно и грустно.
Варианты которые я вижу (и на которую меня тут натолкнули):
1) Забивать на миграцию и работать всегда с теми данными, которые имеются, а так же доп. логика на все кейсы, когда этих данных нет (дефолтные значения, маппинг, проброс ошибок).
Например, нужно добавить новое поле в класс, а в старых документах его нет => при чтении, если в документе отсутствует поле, добавляем некое дефолтное значение при создании класса.
Нужно удалить поле — оно просто игнорируется.
2) Сделать общую логику миграции на клиенте. Хранить каждый документ с номером текущей версии и мигрировать до актуальной при чтении документа при необходимости.
Например, нужно добавить поле.
При чтении видим, что версия документа меньше текущей на устройстве.
Производим миграцию документа до текущей версии, т.е. добавляем новое поле.
Отправляем новую версию документа на сервер для перезаписи старого.
Работаем дальше.
У обоих подходов видятся плюсы и минусы.
Первый вариант очевидно проще.
Второй кажется оверхедом, однако в какой-то мере выглядит как тот же первый, но более структурированый, что плюс.
Гуглеж тоже не упростил задачу.
В общем.
Для меня это первый реальный опыт работы с NoSQL хранилищем как основной БД, поэтому хочется узнать как это обычно делают и как принято, чтобы не нагородить хероты сразу же.
Что скажете?
AD
Копировать все данные на новую схему и свапать коллекции
AD
Есть ещё один вариант - не мигрировать

KD
Звучит как та же миграция, только без версионности.
IP
Резюме, пожалуйста. Не позволяю себе тратить время на такой бред.
Э
А сидеть в чатике полдня норм? Вывод такой - нода затрачивает меньше ресурсов, меньше страдает экология, меньше бабок платить
Э
Топовый канал