e
Андрей
Ввести с клавиатуры два натуральных числа n, k. Построить все разбиения Р (n, k) числа n на k слагаемых так, что количество шагов, необходимых для построения каждого следующего разбиения, ограничена константой, не зависящей от n.
Найти все возможные разбиения числа можно способом похожим на stars and bars, а добавив в алгоритм пару дополнительных проверок, получить требуемый результат - комбинации с заданным количеством слагаемых и неповторяющимися числами.
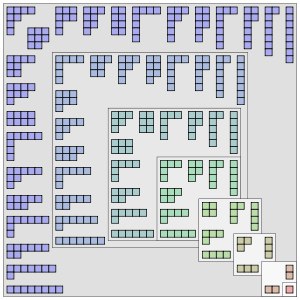
Удобнее объяснять графически:
1) берём число 9 и представляем его в виде восьмёрок (единицы слишком похожи на вертикальную черту, которая будет служить разделителем)
8 8 8 8 8 8 8 8 8
2) затем разделяем эти восьмёрки на правую и левую часть с помощью вертикальной черты (bar)
8 8 8 8 8 8 8 8 8 | = 9 0
8 8 8 8 8 8 8 8 | 8 = 8 1
8 8 8 8 8 8 8 | 8 8 = 7 2
8 8 8 8 8 8 | 8 8 8 = 6 3
8 8 8 8 8 | 8 8 8 8 = 5 4
8 8 8 8 | 8 8 8 8 8 = 4 5
8 8 8 | 8 8 8 8 8 8 = 3 6
8 8 | 8 8 8 8 8 8 8 = 2 7
8 | 8 8 8 8 8 8 8 8 = 1 8
3) Если количество восьмёрок в правой части меньше 1, дальнейшее деление невозможно -> очередная комбинация найдена, иначе фиксируем левую часть и ищем варианты разбиений для правой части, то есть возвращаемся на пункт 1 и повторяем алгоритм для числа в правой части. Пример:
8 8 8 8 8 8 | 8 8 8 = 6 3
правая часть равна 3, фиксируем (запоминаем) левую часть и повторяем алгоритм для тройки
8 8 8 8 8 8 8 8 8 = 3 0
8 8 8 8 8 8 8 8 | 8 = 2 1
8 8 8 8 8 8 8 | 8 8 = 1 2
Рекурсивная реализация на Python:
Удобнее объяснять графически:
1) берём число 9 и представляем его в виде восьмёрок (единицы слишком похожи на вертикальную черту, которая будет служить разделителем)
8 8 8 8 8 8 8 8 8
2) затем разделяем эти восьмёрки на правую и левую часть с помощью вертикальной черты (bar)
8 8 8 8 8 8 8 8 8 | = 9 0
8 8 8 8 8 8 8 8 | 8 = 8 1
8 8 8 8 8 8 8 | 8 8 = 7 2
8 8 8 8 8 8 | 8 8 8 = 6 3
8 8 8 8 8 | 8 8 8 8 = 5 4
8 8 8 8 | 8 8 8 8 8 = 4 5
8 8 8 | 8 8 8 8 8 8 = 3 6
8 8 | 8 8 8 8 8 8 8 = 2 7
8 | 8 8 8 8 8 8 8 8 = 1 8
3) Если количество восьмёрок в правой части меньше 1, дальнейшее деление невозможно -> очередная комбинация найдена, иначе фиксируем левую часть и ищем варианты разбиений для правой части, то есть возвращаемся на пункт 1 и повторяем алгоритм для числа в правой части. Пример:
8 8 8 8 8 8 | 8 8 8 = 6 3
правая часть равна 3, фиксируем (запоминаем) левую часть и повторяем алгоритм для тройки
8 8 8 8 8 8 8 8 8 = 3 0
8 8 8 8 8 8 8 8 | 8 = 2 1
8 8 8 8 8 8 8 | 8 8 = 1 2
Рекурсивная реализация на Python:
def partition(new_comb, residue, combinations):
if len(new_comb) > k:
return
if len(new_comb) == k and residue < 1:
combinations.append('+'.join(map(str, new_comb)))
return
for cur_num in range(residue, 0, -1):
if not new_comb or cur_num < new_comb[-1]:
partition(new_comb + [cur_num], residue - cur_num, combinations)
combinations = []
num = 9
k = 3
partition([], num, combinations)
print(*combinations, sep='\n')