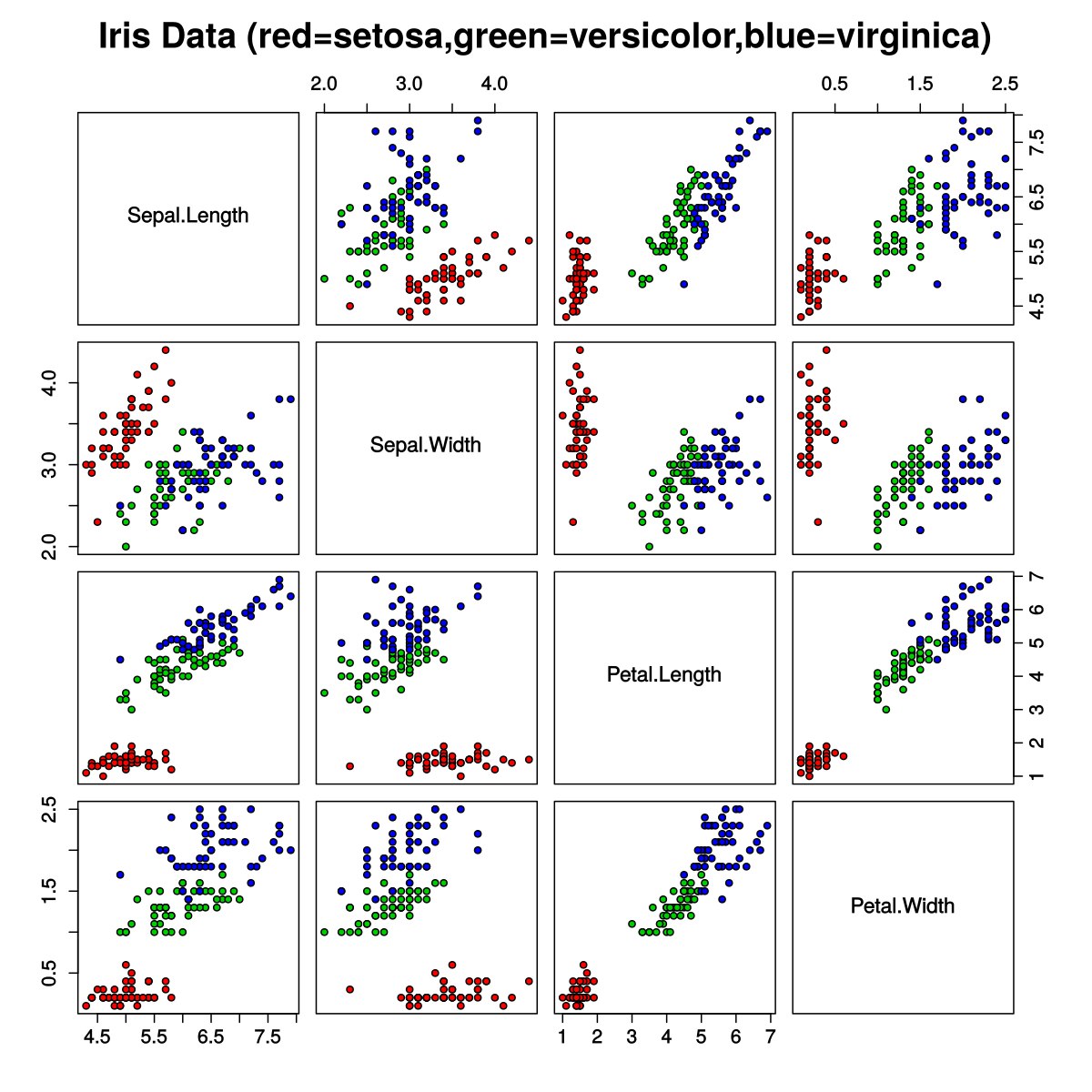
Добрый день. Вопрос по логистической регрессии. Моя регрессия должна показать уйдет клиент или нет в зависимости от локации. Всего 4 локации. Я вижу, что локация 1 стат значимо не отличается от базовой локации (то, что в интерсепте), как и локация 3. Нам нужно исключить эти локации из модели. Мой вопрос: как это правильно сделать?
Мое предположение было таким: закодировать так: если это локация базовая или первая или третья, то 0. если это локация 2, то 1. И после этого снова запускать логист.регрессию. Так нужно делать?
1. Обычно в логистической регрессии работают с численными переменными-предикторами, а не факторными/номинальными. Использование последних уже является логистической регрессией с контрастами или что-то в этом роде
2. Соответсвенно Intercept - это параметр регрессии на константу и к кодированию отношения не имеет
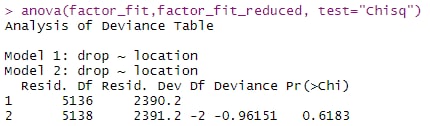
3. Переменные можно просто исключить из модели. Собственно т.к. они не значимы, то и удаление/добавление таки переменных не должно сильно влиять на модель. Ваша Anova об этом и говорит.
4. Для того чтобы параметры регресси можно было анализировать на существенность то рекоменудется делать центрирование и нормирование. Тогда можно будет наглядно увидеть, что одни параметры существенные, а другие нет. Существенность и значимость - это разные вещи, естественно.
5. Обычно исключение переменных из модели линейной регрессии делается для того чтобы исключить мультиколлиниарность т.е. исключить многократное влияние одной экзогенной переменной