E
Dm Kb
1. Обычно в логистической регрессии работают с численными переменными-предикторами, а не факторными/номинальными. Использование последних уже является логистической регрессией с контрастами или что-то в этом роде
2. Соответсвенно Intercept - это параметр регрессии на константу и к кодированию отношения не имеет
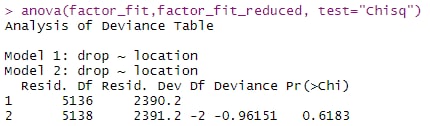
3. Переменные можно просто исключить из модели. Собственно т.к. они не значимы, то и удаление/добавление таки переменных не должно сильно влиять на модель. Ваша Anova об этом и говорит.
4. Для того чтобы параметры регресси можно было анализировать на существенность то рекоменудется делать центрирование и нормирование. Тогда можно будет наглядно увидеть, что одни параметры существенные, а другие нет. Существенность и значимость - это разные вещи, естественно.
5. Обычно исключение переменных из модели линейной регрессии делается для того чтобы исключить мультиколлиниарность т.е. исключить многократное влияние одной экзогенной переменной
2. Соответсвенно Intercept - это параметр регрессии на константу и к кодированию отношения не имеет
3. Переменные можно просто исключить из модели. Собственно т.к. они не значимы, то и удаление/добавление таки переменных не должно сильно влиять на модель. Ваша Anova об этом и говорит.
4. Для того чтобы параметры регресси можно было анализировать на существенность то рекоменудется делать центрирование и нормирование. Тогда можно будет наглядно увидеть, что одни параметры существенные, а другие нет. Существенность и значимость - это разные вещи, естественно.
5. Обычно исключение переменных из модели линейной регрессии делается для того чтобы исключить мультиколлиниарность т.е. исключить многократное влияние одной экзогенной переменной
Под существенностью Вы имеете в виду как сильно влияет на зависимую переменную независимая переменная, т.е значение коэффициентов (при условии, что мы стандартизировали переменные), под значимостью p-value?
О факторных и численных переменных я думала, как и Igor
О факторных и численных переменных я думала, как и Igor