



DB
Size: a a a
2021 June 10
2021 June 11
E

Здравствуйте. Подскажите, пожалуйста функцию для того, чтобы сделать перенос слов на таком графике. Т.е. чтобы длинные словосочетания разбивались на несколько строк. Например, такие слова на графике, как EARTH SCIENCES, OTHER EARTH SCIENCES. (График не мой. Взят для примера с сайта https://rpubs.com/jonathanyu/ausopendata17-kw-cooccurences-correlations)
E
Спасибо, если кто-то хотел ответить. Нашла ответ сама с помощью
geom_node_text(aes(label = stringr::str_wrap(Label, 10)),family="serif", size = 3)JS
всем доброго дня, вопрос для практикующих ML:
1) вот есть у меня "правильный" CV, это когда всякие там средние и прочие штуки - считаются строго на train-фолдах, а потом применяются на тест-фолде, через пайплайн, и вот пробую target-mean-encoding (и да, он smoothed) - реализовал, получил скор на CV и "чистом" тесте (модель этих данных не видела)
2) потом сделал такую штуку - когда весь трейн (внутри текущего сплита CV) бьется еще раз на фолды - и на них делается "правильный" target-mean-encoding (среднее таргета считаем по трейну, применяем на тестовом фолде), во внешнем CV для кодирования факторов в тестовом фолде применяем среднее по всему трейну. И вот во втором случае я получил хуже скор на CV и тесте, соразмерно. Вопрос - если у нас честный CV - а надо ли еще и трейн бить на фолды и там делать "правильный" target-mean-encoding?
самому думается, что если CV честный (все считаем без учета тестовой части) - то указанное выше делать не нужно
что думаете?
1) вот есть у меня "правильный" CV, это когда всякие там средние и прочие штуки - считаются строго на train-фолдах, а потом применяются на тест-фолде, через пайплайн, и вот пробую target-mean-encoding (и да, он smoothed) - реализовал, получил скор на CV и "чистом" тесте (модель этих данных не видела)
2) потом сделал такую штуку - когда весь трейн (внутри текущего сплита CV) бьется еще раз на фолды - и на них делается "правильный" target-mean-encoding (среднее таргета считаем по трейну, применяем на тестовом фолде), во внешнем CV для кодирования факторов в тестовом фолде применяем среднее по всему трейну. И вот во втором случае я получил хуже скор на CV и тесте, соразмерно. Вопрос - если у нас честный CV - а надо ли еще и трейн бить на фолды и там делать "правильный" target-mean-encoding?
самому думается, что если CV честный (все считаем без учета тестовой части) - то указанное выше делать не нужно
что думаете?
JS
блин, пока печатал, ошибку нашел %) сейчас пересчитаю, может и удалить вопрос придется
A
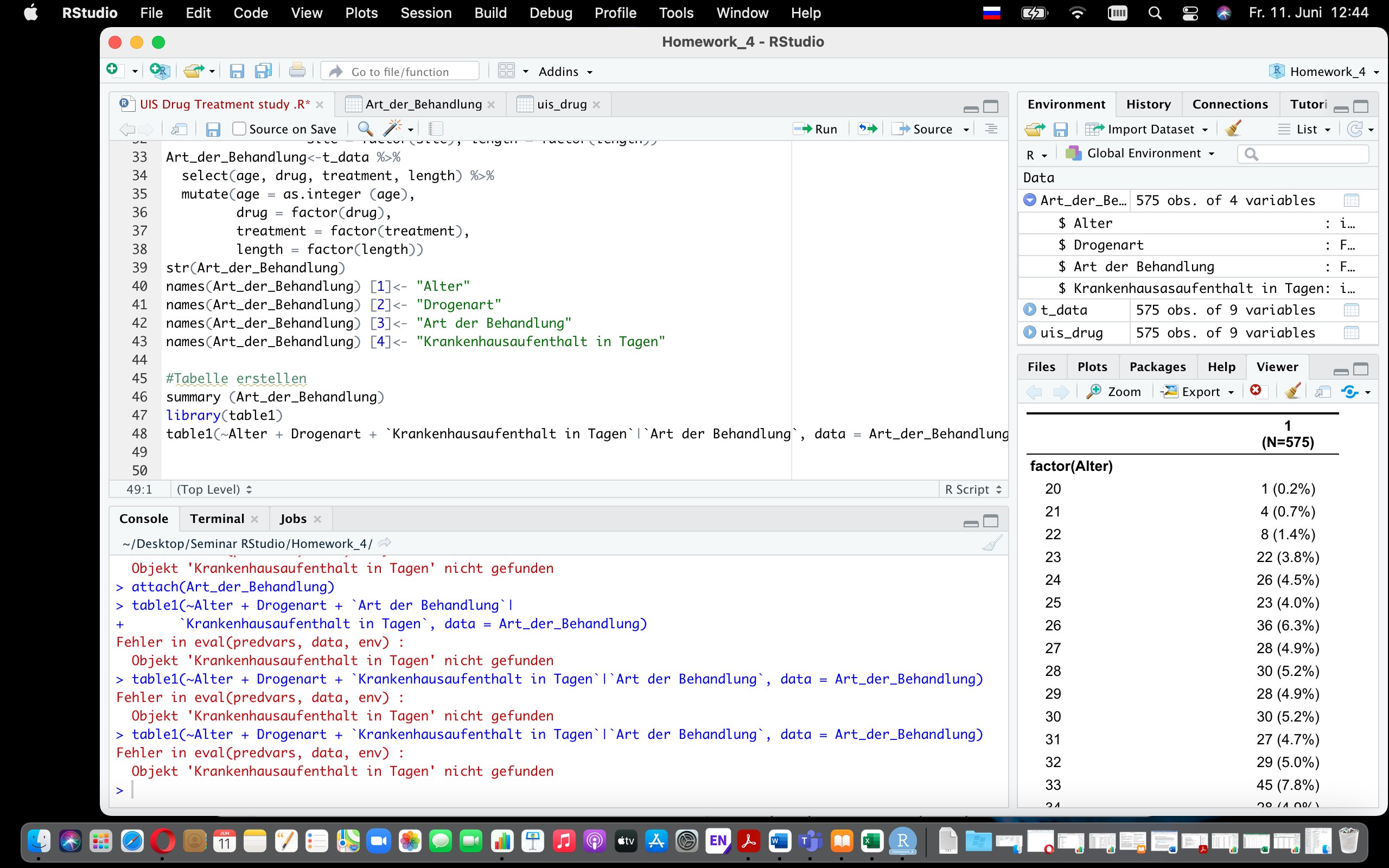
добрый день, может кто-нибудь помочь? где ошибка?
A
DK
с англоязычной локалью вам бы помогли быстрее
DB
summary что выдаёт?
IS
с учетом того, что в table1 похоже, что используется формула, использовать бэктики нехорошо.
A
вам в table1 по другому имена переменных указать, по идее в кавычках. если я правильно понял, что вам нужны эти колонки из таблицы Art_der_behandlung
JS
вопрос актуален, все равно CV-скор ниже, если делаем фолды внутри фолдов для target mean encoding внутри train части внутри CV-итерации
RZ
["1"] <- "Alter"
A
еще гипотеза - у вас ошибка в таблице в слове
Krankenhausaufenthaltколонка называется
KrankenhausasaufenthaltDB
С кавычками проблема
DB
По подсветке кода видно
A
Расставила кавычки, пишет ошибка : in terms.formula(fi,...): invalid in extractVars🙈
A
Блин, спасибо, ну как так🙈
A
Одна опечатка и всё🤦♀️
A
суровые немецкие переменные)