Не будем кривить душой, на деле межхостовый RTT сравним со чтением локального NVMe. Вопрос в другом: в каких кейсах действительно критична задержка на чтение малым блоком не 100, а 50 us? И почему сеть так спроектировали, что в неё можно упереться при worst scenario.
эээ. Так сравнивать надо не с тем, что в теории МОЖЕТ дать локальный NVMe, а с тем, что дает СХД в итоге на базе дисков с локальными NVMe. И ответ там - сотни мкс просто потому что, что тормозит не сеть, а выше по стеку.
Мне интересно, я до сих пор думаю что не может такого быть что сходить на nvme из процессора по скорости то же самое что и по сети, как-то это странно.
локальный - безусловно. Но вот только проблема в том, что над ним дохрена логики и процессов, которые добавляют latency заметно больше того, что дает сеть
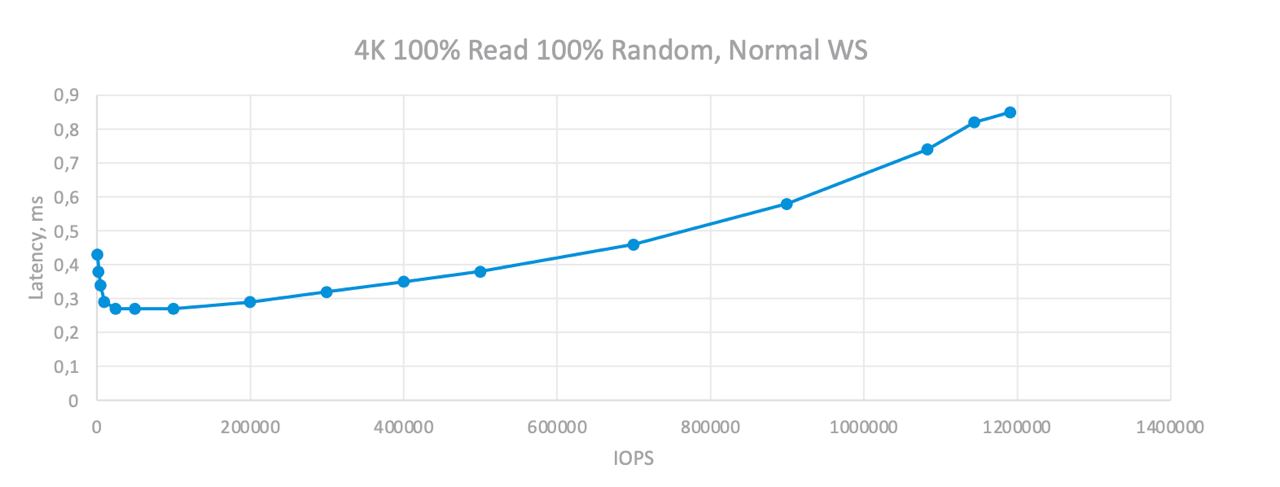
если быть точным то вот так: - чтение хоть nvme, хоть ssd 4k ~ 0.1ms (100us). не веришь - проверь fio -iodepth=1 -rw=randread. быстрее только Optane и ещё чувак один в чатике витастора говорит что Intel 5510 (но последнее пока не гарантированно) - обращение по сети за чтением 4k - порядка 50us. RDMA 20-30us. если тормозная сеть то может быть и 100us и выше