SK
> Catalyst.RL сейчас - это кажись первый RL framework, который нормально работает с такими нагрузками
RLlib ?
RLlib ?
ага, контрибьютил туда
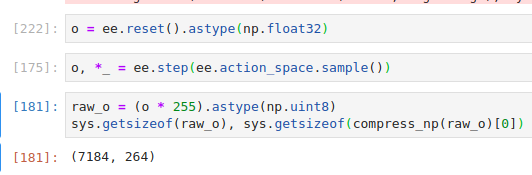
но у них нет реального Distributed Training на кучи машин...легко + не настолько resource efficient - ребятки все так хранят в RAM
ах да, там еще TF и кастомизировать - боль (кастомизировал им DDPG и друзей DDPG )
но концептуально фреймворк хороший, вдохновляюсь им
но у них нет реального Distributed Training на кучи машин...легко + не настолько resource efficient - ребятки все так хранят в RAM
ах да, там еще TF и кастомизировать - боль (кастомизировал им DDPG и друзей DDPG )
но концептуально фреймворк хороший, вдохновляюсь им