SK
Борис Добров
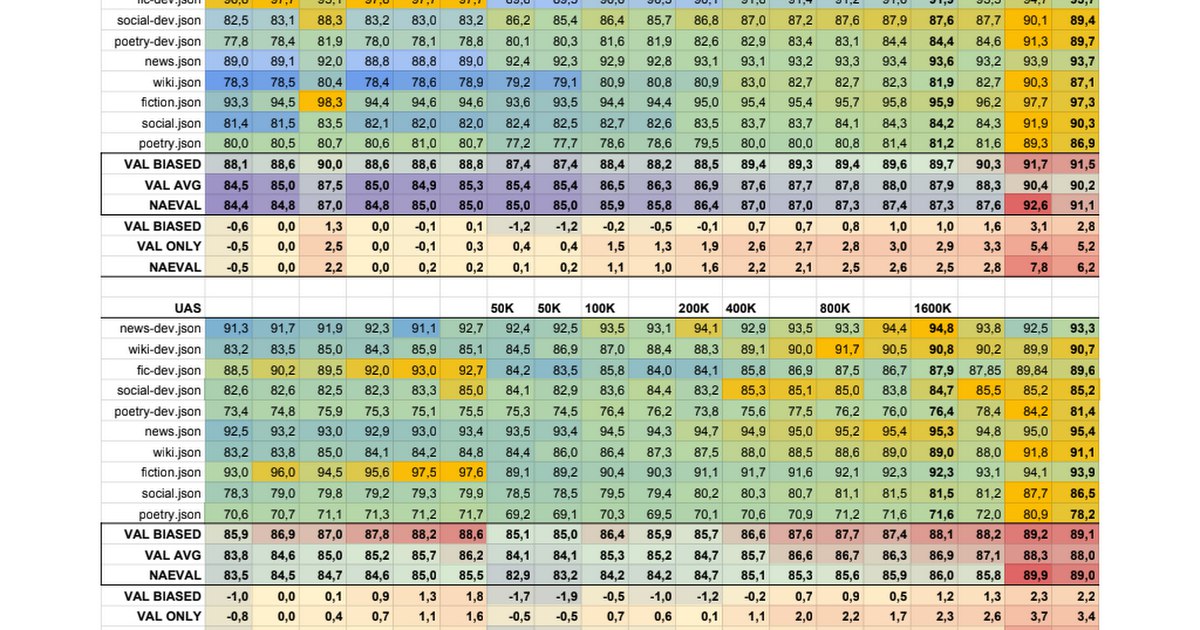
И будет ли обоснованием использовать bert при росте 5%
хочу попробовать, пока время и ресурсы есть.
Size: a a a
SK
SK
БД
БД
AZ
YB
YB
➔m
VS
AC
AC
AC
VS
МП
МП
KK
d
from torch.utils.data import Dataset, DataLoaderИ вперёд
KK
from torch.utils.data import Dataset, DataLoaderИ вперёд
d
build_vocabulary
Field