Очень часто приходится слышать термины Data Warehouse, Data Lake, Data Hub, при этом часто произносящие их не задумываются о реальных отличиях этих понятий. В блоге The Startup на Medium хороший обзор на английском [1] об отличии и сходствах таких понятий как:
- Data Lake
- Data Hub
- Data Virtualization / Data Federation
- Data Warehouse
- Operational Data Store
Все отличия объяснены на редкость доходчиво, я как-нибудь найду время перевести этот текст на русский язык.
Краткий ликбез такой:
-
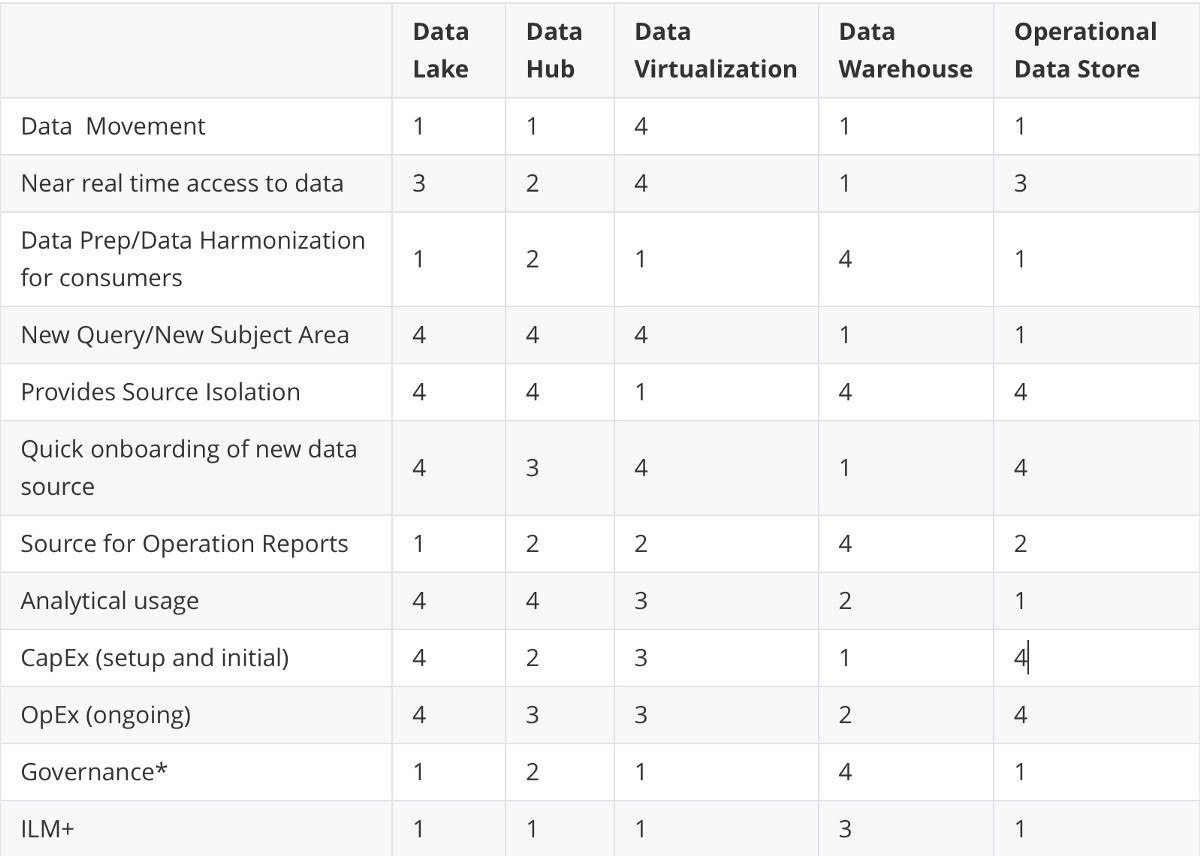
Data Lake (Озеро данных) - это несвязанные данные удобные для data science и аналитической работы. Работает в ситуации возникновения задач и адаптации данных под конкретные задачи.
-
Data Hub - это данные собранные в одно хранилище с некоторой работой по преобразованию и обработке. Больше форматирования, контроля и управления по сравнениею с озером данных.
-
Data Virtualization/Data Federation - это пробрасывание виртуальных связей между источниками, иногда уже начало ведение общих справочников. Больше ориентировано на данные реального времени и интеграцию
-
Data Warehouse - наиболее подходит для подготовки управленческих отчетов, готовится на основе масштабной обработки данных, контроля справочников и так далее. Очень негибко, но наиболее пригодно к управлению циклом жизни данных
-
Operational Data Store - это, как правила, зеркала для хранения транзакционных баз данных чтобы не затрагивать сами базы данных работающих в режиме реального времени.
Ссылки:
[1]
https://medium.com/swlh/the-5-data-store-patterns-data-lakes-data-hubs-data-virtualization-data-federation-data-27fd75486e2c#opendata #data #datalakes #datamanagement #datagovernance