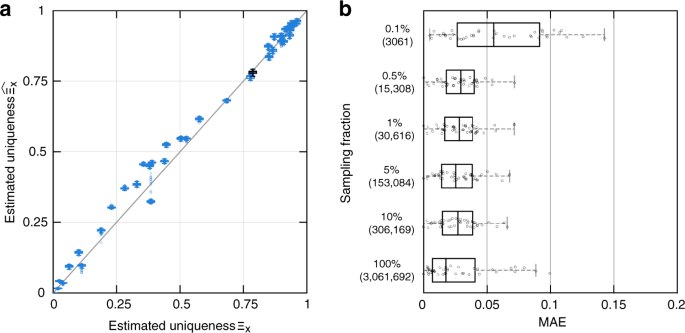
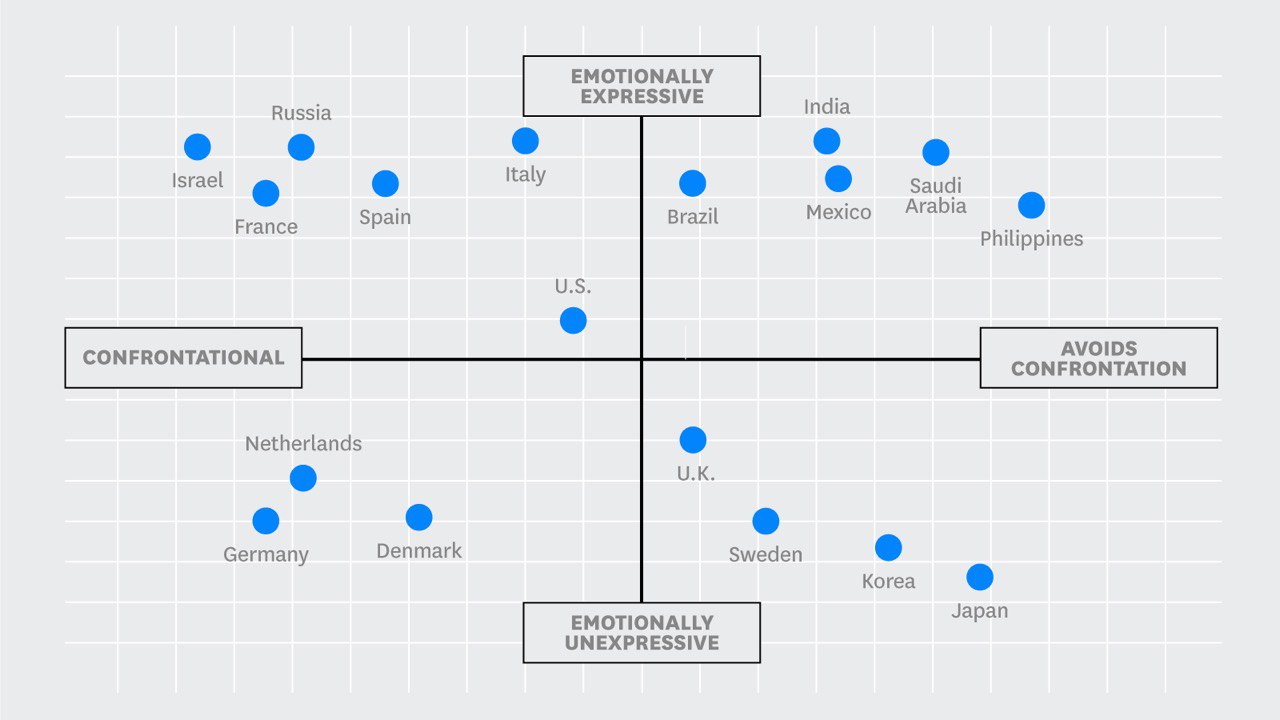
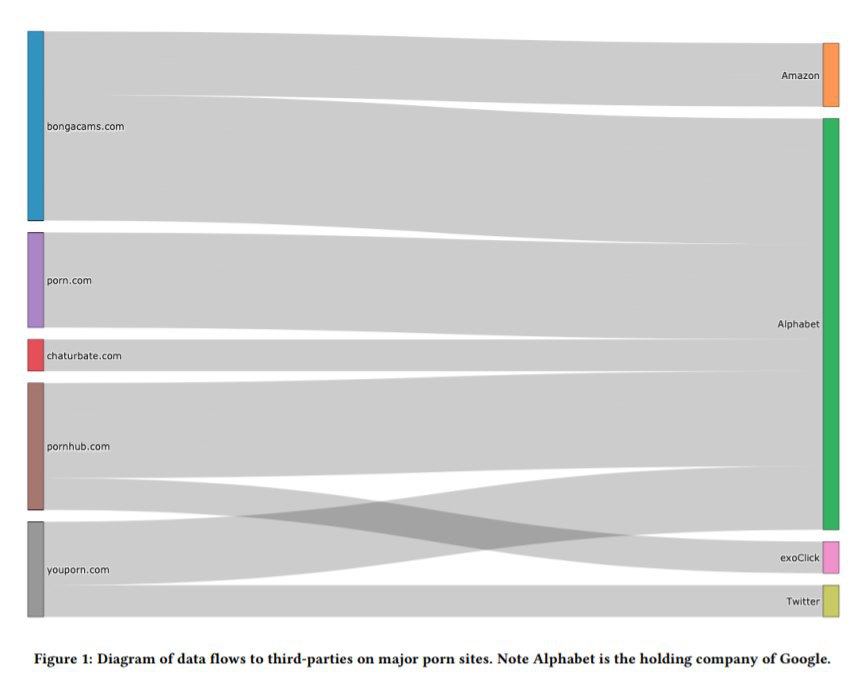
Насколько анонимной будет ваша анкета, если убрать из неё только ваше имя? Много ли в вашем квартале живёт людей вашего пола, родившихся в один день с вами?
Британские исследователи обработали несколько сотен датасетов, в том числе из переписи населения США, и создали матмодель, оценивающую вероятность точной идентификации человека по его неполным персональным данным. Гражданина США можно идентифицировать по почтовому индексу, полу и дате рождения с точностью 81%. 15 демографических характеристик дают 99,98% шанс на точную деанонимизацию. Вот здесь вы сами можете добавлять в комбинацию разные данные и смотреть, как это влияет на точность идентификации.
Удаление строки с именем пользователя ещё не делает базу с персональными данными безопасной. Как показывает эта работа, любой анонимизированный датасет с личной информацией можно считать таким лишь условно.
И ещё раз посоветую вам прочитать историю о том, как ничего не подозревающих пользователей деанонимизировали по купленным на чёрном рынке историям посещений браузера.
Британские исследователи обработали несколько сотен датасетов, в том числе из переписи населения США, и создали матмодель, оценивающую вероятность точной идентификации человека по его неполным персональным данным. Гражданина США можно идентифицировать по почтовому индексу, полу и дате рождения с точностью 81%. 15 демографических характеристик дают 99,98% шанс на точную деанонимизацию. Вот здесь вы сами можете добавлять в комбинацию разные данные и смотреть, как это влияет на точность идентификации.
Удаление строки с именем пользователя ещё не делает базу с персональными данными безопасной. Как показывает эта работа, любой анонимизированный датасет с личной информацией можно считать таким лишь условно.
И ещё раз посоветую вам прочитать историю о том, как ничего не подозревающих пользователей деанонимизировали по купленным на чёрном рынке историям посещений браузера.