



Size: a a a
2019 October 18
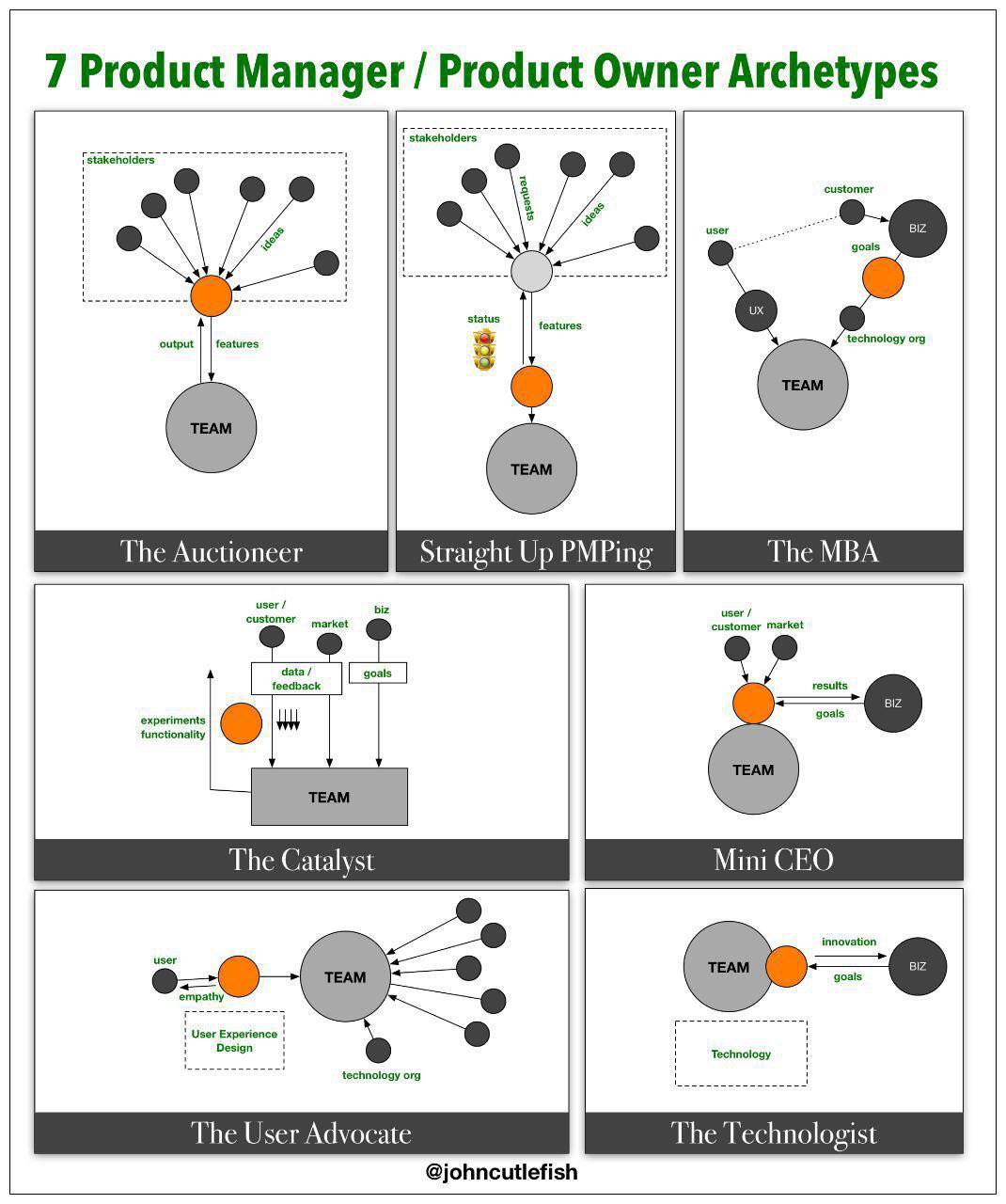
2019 October 21
Для mvp пойдёт)
2019 October 22
Harvard Business Review (HBR)
Harvard Business Review (HBR)
Личная эффективность
https://t.me/watchandread/136
Управление изменениями
https://t.me/watchandread/134
Стратегия
https://t.me/watchandread/132
Эмоциональный интеллект
https://t.me/watchandread/130
Via @afinaagency
Harvard Business Review (HBR)
Личная эффективность
https://t.me/watchandread/136
Управление изменениями
https://t.me/watchandread/134
Стратегия
https://t.me/watchandread/132
Эмоциональный интеллект
https://t.me/watchandread/130
Via @afinaagency

2019 October 23
Harvard Business Review (HBR)
Управление бизнесом
https://t.me/watchandread/128
Методы принятия решений
https://t.me/watchandread/126
Управление персоналом
https://t.me/watchandread/124
Инновационный менеджмент
https://t.me/watchandread/122
Via @afinaagency
Управление бизнесом
https://t.me/watchandread/128
Методы принятия решений
https://t.me/watchandread/126
Управление персоналом
https://t.me/watchandread/124
Инновационный менеджмент
https://t.me/watchandread/122
Via @afinaagency

#TRENDSproVenture
Как крупнейшие компании получили своих первых клиентов?
А тут интереснейшая подборка – текст, но красиво оформленный.
Ну и по сути – какие действия основателей позволили завоевать клиентов. Выбирай, не хочу. Например, Zoom, который выходил на рынок, который (казалось) уже занял Skype и были другие конкуренты.
А они просто разместили биллборд со словами “Video Conferencing That Doesn’t Suck”. И предложение попробовать Zoom. Бесплатно.
Вот так компания получила своих первых “адоптеров”.
Кликаем на остальные и с интересом читаем.
via @proVenture
https://earlyusergrowth.com/startups/#zoom
Как крупнейшие компании получили своих первых клиентов?
А тут интереснейшая подборка – текст, но красиво оформленный.
Ну и по сути – какие действия основателей позволили завоевать клиентов. Выбирай, не хочу. Например, Zoom, который выходил на рынок, который (казалось) уже занял Skype и были другие конкуренты.
А они просто разместили биллборд со словами “Video Conferencing That Doesn’t Suck”. И предложение попробовать Zoom. Бесплатно.
Вот так компания получила своих первых “адоптеров”.
Кликаем на остальные и с интересом читаем.
via @proVenture
https://earlyusergrowth.com/startups/#zoom

2019 October 27
Киберспорт и правда показывает хороший тренд, вот ребята заказали сайт для новой сети клубов whykick.webflow.io
2019 October 28
#likethebossdoes
Десять рецептов успеха от Трампа
1. Никогда не сдавайтесь! Не расслабляйтесь, находясь постоянно в своей зоне комфорта.
2. Любите свое дело! Если любите свое дело, то оно никогда не станет для вас обычной работой.
3. Сосредоточтесь! Спросите себя: о чем я должен думать в данный момент? Отключитесь от лишнего и мешающего.
4. Сохраняйте направление движения и продвигайтесь вперед! Слушайте применяйте и действуйте. Не мешкайте.
5. Чувствуйте себя победителем! Это позволит вам сконцентрироваться на нужном направлении.
6. Будьте упорным! Упорство может творить чудеса.
7. Будьте удачливым! Старая поговорка гласит: "Чем упорнее работаешь, тем ближе удача" И она абсолютно справедлива.
8. Поверьте в себя! Если вы сами не верите в себя, то кто в вас поверит? Вы целая армия которая состоит из одного человека!
9. Спросите себя: Чего я пытаюсь не замечать? Возможно, перед вами открываются перкрасные возможности, хотя ситуация выглядит не самым радужным способом.
10. Думайте о решении, а не о проблеме. И никогда не сдавайтесь! Никогда, никогда никогда не сдавайтесь! Эту мысль стоит повторить множество раз. (Тут товарищ Трамп цитирует Черчиля )))
Десять рецептов успеха от Трампа
1. Никогда не сдавайтесь! Не расслабляйтесь, находясь постоянно в своей зоне комфорта.
2. Любите свое дело! Если любите свое дело, то оно никогда не станет для вас обычной работой.
3. Сосредоточтесь! Спросите себя: о чем я должен думать в данный момент? Отключитесь от лишнего и мешающего.
4. Сохраняйте направление движения и продвигайтесь вперед! Слушайте применяйте и действуйте. Не мешкайте.
5. Чувствуйте себя победителем! Это позволит вам сконцентрироваться на нужном направлении.
6. Будьте упорным! Упорство может творить чудеса.
7. Будьте удачливым! Старая поговорка гласит: "Чем упорнее работаешь, тем ближе удача" И она абсолютно справедлива.
8. Поверьте в себя! Если вы сами не верите в себя, то кто в вас поверит? Вы целая армия которая состоит из одного человека!
9. Спросите себя: Чего я пытаюсь не замечать? Возможно, перед вами открываются перкрасные возможности, хотя ситуация выглядит не самым радужным способом.
10. Думайте о решении, а не о проблеме. И никогда не сдавайтесь! Никогда, никогда никогда не сдавайтесь! Эту мысль стоит повторить множество раз. (Тут товарищ Трамп цитирует Черчиля )))


почему-то фотография не прикрепилась, вот отдельно)
2019 October 29
Друзья Продакты! Как я и говорил прохожу accelerator в PU, очень нужны ваши ответы касательно поиска работы, опрос короткий и займет у вас меньше минуты
Ответившим будет прислан уникальный контент для продактов (статья про продуктовые команды от Marty Cagan)
Опрос тут: https://yanlukashin.typeform.com/to/nTxSBB
Ответившим будет прислан уникальный контент для продактов (статья про продуктовые команды от Marty Cagan)
Опрос тут: https://yanlukashin.typeform.com/to/nTxSBB

2019 November 01
Привет друзья!
Давно ничего не писал, исправляюсь!
1) Удалил с телефона все мессенджеры/соц.сети и почтовые клиенты, остался только скайп для созвона с группой в ProductSense.
Зачем я это сделал?
Зашел в экранное время телефона и офигел, всем советую сделать это.
(статья по теме - https://medium.com/better-humans/how-to-set-up-your-iphone-for-productivity-focus-and-your-own-longevity-bb27a68cc3d8)
2) Разочаровался в своем убийце HH, решил сделать из него HR-агентство для продактов, вот редизайн: www.productwork.ru
Почему? Решение принято после простейшего анализа юнит экономики в акселлераторе PU, а еще после анализа ответов на опрос понял что продактам не нужны вакансии им нужна работа, а компаниям не нужны анкеты/резюме им нужны работники, как эту задачу решить буду подумать.
3) Продолжаю работать над маркетплейсом готовых сайтов: www.afinaagency.com
Уже добавлено 50 шаблонов сайтов для tilda, за ближайшую неделю будет добавлено еще около 100 шаблонов для webflow, запуск рекламы на днях, о результатах отпишусь!
Коротко о проекте: Это маркетплейс шаблонов для тильды.Конкуренты: TemplateMonster, Weblium.
4) А еще последние пара дней заполнения анкет грин кард кто забыл заполняйте (сайт для отправки анкет http://dvlottery.state.gov) о том как заполнять сделал инструкцию - https://xvx4i.weblium.site/blog
Давно ничего не писал, исправляюсь!
1) Удалил с телефона все мессенджеры/соц.сети и почтовые клиенты, остался только скайп для созвона с группой в ProductSense.
Зачем я это сделал?
Зашел в экранное время телефона и офигел, всем советую сделать это.
(статья по теме - https://medium.com/better-humans/how-to-set-up-your-iphone-for-productivity-focus-and-your-own-longevity-bb27a68cc3d8)
2) Разочаровался в своем убийце HH, решил сделать из него HR-агентство для продактов, вот редизайн: www.productwork.ru
Почему? Решение принято после простейшего анализа юнит экономики в акселлераторе PU, а еще после анализа ответов на опрос понял что продактам не нужны вакансии им нужна работа, а компаниям не нужны анкеты/резюме им нужны работники, как эту задачу решить буду подумать.
3) Продолжаю работать над маркетплейсом готовых сайтов: www.afinaagency.com
Уже добавлено 50 шаблонов сайтов для tilda, за ближайшую неделю будет добавлено еще около 100 шаблонов для webflow, запуск рекламы на днях, о результатах отпишусь!
Коротко о проекте: Это маркетплейс шаблонов для тильды.Конкуренты: TemplateMonster, Weblium.
4) А еще последние пара дней заполнения анкет грин кард кто забыл заполняйте (сайт для отправки анкет http://dvlottery.state.gov) о том как заполнять сделал инструкцию - https://xvx4i.weblium.site/blog
2019 November 02
Крутость этой новости просто запредельная
Размышления о будущем машинного обучения, вызванные очередными успехами AlphaStar
AlphaStar — это алгоритм для игры в StarCraft от компании DeepBrain, той самой, которая когда-то победила человека в го: вначале чемпиона Европы, затем Ли Седоля, а потом уже и сильнейшего из людей, Кэ Цзе. StarCraft — игра намного более сложная по сравнению с го и уж, тем более, по сравнению с шахматами: количество возможных позиций актуально бесконечно с позиции любой разумной прагматики, в игре неполная информация (действия противника можно понять только если хорошо разведывать), ну и так далее.
Я к StarCraft отношусь с большой нежностью, поэтому за приключениями AlphaStar следил с большим любопытством. Горячие публичные обсуждения начались в январе 2019-го года, когда в выставочном матче AlphaStar обыграл очень сильного профессионального игрока. Про это можно почитать в блоге DeepMind, хорошая русскоязычная адаптация есть на Хабре. Там же (да и в других местах) в подробностях обсуждали, что алгоритм всё-таки делает слишком много кликов; не было понятно, видит ли он карту целиком (люди так не умеют) или же только небольшой её кусочек; были и какие-то более мелкие подозрительные моменты.
Я к этим подозрениям всегда относился очень спокойно. Даже если алгоритм кликает слишком быстро, всё равно он кликает на ранее недостижимом (для алгоритмов) уровне умности. Два моих любимых момента: в первом AplhaStar берёт человеческие войска в «котёл», во втором — производит дополнительного рабочего, что резко расходится с общепринятой практикой на начальной стадии игры, оцените эмоции комментатора! Конечно, лишние или хотя бы более точные клики очень помогают победить, но вот эти чисто тактические действия, конечно, никак с кликами не связаны. Если хочешь выиграть за количество кликов — будешь играть совсем по-другому.
Короче, было ясно, что получение совсем честного и при этом круто играющего алгоритма — дело времени. И вот время пришло. AlphaStar начал играть на BattleNet и два дня назад прошёл в высшую профессиональную лигу. Про это вышло сообщение в блоге DeepMind, а ещё есть статья в Nature. Заявляется несколько очень важных апдейтов:
— алгоритм теперь лимитирован примерно так же, как и человек: может действовать только в рамках того, что попадает в область обзора камеры;
— умеет играть за все три игровые расы;
— учится, что называется, from scratch, полностью автоматически. В прошлых сериях строились целые стратегические карты и из множества агентов для будущей игры ещё нужно было как-то выбирать.
Такие обновления в алгоритме и их результативность — это очень-очень круто, мы (человечество) всё лучше начинаем нащупывать подходы в обучении с подкреплением. Обучение с подкреплением (reinforcement learning) — это когда есть система, на неё можно разными способами действовать, в ответ получать реакции (какой-то профит, грубо говоря) и учиться действовать так, чтобы профита было как можно больше.
В шахматах, го или даже старкрафте этот подход работает: возьмём большой компьютер, будем много-много раз разыгрывать партии, смотреть, какие ходы ведут к победе и впоследствии делать такие почаще.
К сожалению, прямое переложение этих методов на физический мир (мне) очень трудно себе представить. Скажем, если делать reinforcement learning в обычном человеческом образовании, придётся каких-то вполне конкретных людей направлять по неоптимальным дорогам развития только для того, чтобы выучить, что они неоптимальны. Да и «разыграть партию» в приложениях, отличных от игр, не всегда возможно. Особенно в нужных количествах.
Поэтому по меньшей мере половина авторов нашего канала придерживается позиции, что будущее принадлежит не обучению с подкреплением, а более прогрессивным методам — например, imitation learning'у. Про него есть отличный туториал с ICML 2018, а ещё есть всякие забавные видосы — например, как роботы учатся наливать воду из бутыки.
Алексей Шаграев
AlphaStar — это алгоритм для игры в StarCraft от компании DeepBrain, той самой, которая когда-то победила человека в го: вначале чемпиона Европы, затем Ли Седоля, а потом уже и сильнейшего из людей, Кэ Цзе. StarCraft — игра намного более сложная по сравнению с го и уж, тем более, по сравнению с шахматами: количество возможных позиций актуально бесконечно с позиции любой разумной прагматики, в игре неполная информация (действия противника можно понять только если хорошо разведывать), ну и так далее.
Я к StarCraft отношусь с большой нежностью, поэтому за приключениями AlphaStar следил с большим любопытством. Горячие публичные обсуждения начались в январе 2019-го года, когда в выставочном матче AlphaStar обыграл очень сильного профессионального игрока. Про это можно почитать в блоге DeepMind, хорошая русскоязычная адаптация есть на Хабре. Там же (да и в других местах) в подробностях обсуждали, что алгоритм всё-таки делает слишком много кликов; не было понятно, видит ли он карту целиком (люди так не умеют) или же только небольшой её кусочек; были и какие-то более мелкие подозрительные моменты.
Я к этим подозрениям всегда относился очень спокойно. Даже если алгоритм кликает слишком быстро, всё равно он кликает на ранее недостижимом (для алгоритмов) уровне умности. Два моих любимых момента: в первом AplhaStar берёт человеческие войска в «котёл», во втором — производит дополнительного рабочего, что резко расходится с общепринятой практикой на начальной стадии игры, оцените эмоции комментатора! Конечно, лишние или хотя бы более точные клики очень помогают победить, но вот эти чисто тактические действия, конечно, никак с кликами не связаны. Если хочешь выиграть за количество кликов — будешь играть совсем по-другому.
Короче, было ясно, что получение совсем честного и при этом круто играющего алгоритма — дело времени. И вот время пришло. AlphaStar начал играть на BattleNet и два дня назад прошёл в высшую профессиональную лигу. Про это вышло сообщение в блоге DeepMind, а ещё есть статья в Nature. Заявляется несколько очень важных апдейтов:
— алгоритм теперь лимитирован примерно так же, как и человек: может действовать только в рамках того, что попадает в область обзора камеры;
— умеет играть за все три игровые расы;
— учится, что называется, from scratch, полностью автоматически. В прошлых сериях строились целые стратегические карты и из множества агентов для будущей игры ещё нужно было как-то выбирать.
Такие обновления в алгоритме и их результативность — это очень-очень круто, мы (человечество) всё лучше начинаем нащупывать подходы в обучении с подкреплением. Обучение с подкреплением (reinforcement learning) — это когда есть система, на неё можно разными способами действовать, в ответ получать реакции (какой-то профит, грубо говоря) и учиться действовать так, чтобы профита было как можно больше.
В шахматах, го или даже старкрафте этот подход работает: возьмём большой компьютер, будем много-много раз разыгрывать партии, смотреть, какие ходы ведут к победе и впоследствии делать такие почаще.
К сожалению, прямое переложение этих методов на физический мир (мне) очень трудно себе представить. Скажем, если делать reinforcement learning в обычном человеческом образовании, придётся каких-то вполне конкретных людей направлять по неоптимальным дорогам развития только для того, чтобы выучить, что они неоптимальны. Да и «разыграть партию» в приложениях, отличных от игр, не всегда возможно. Особенно в нужных количествах.
Поэтому по меньшей мере половина авторов нашего канала придерживается позиции, что будущее принадлежит не обучению с подкреплением, а более прогрессивным методам — например, imitation learning'у. Про него есть отличный туториал с ICML 2018, а ещё есть всякие забавные видосы — например, как роботы учатся наливать воду из бутыки.
Алексей Шаграев

2019 November 03
Когда я только задумал рубрику #likethebossdoes я думал у меня будут проблемы с контентом, я думал что будет мало людей чьей мудростью я хочу поделиться, но оказалось все наоборот, пришлось ввести жесткий ценз на отбор))
Итак очередной выпуск #likethebossdoes
Ричардом Брэнсоном (Richard Branson) сложно не восхищаться. Это уникальный предприниматель, мечтатель и победитель. Брэнсона часто приглашают выступить с лекциями, ведь его слова действительно вдохновляют. Эти цитаты бизнесмена добавят вам уверенности и энтузиазма.
О самобытности
Для меня заниматься бизнесом не значит надеть костюм и угождать стейкхолдерам. Речь о том, чтобы оставаться верным себе, своим идеям и фокусироваться на самом главном.
О позитивном настрое
Моё жизненное кредо — наслаждаться каждой минутой. Я никогда ничего не делаю с мыслью «О нет, сегодня я должен заняться этим».
Бизнесмен должен быть вовлечённым, ему должно быть весело. Это развивает творческие способности.
О предпринимательстве
Вся суть предпринимательства состоит в том, чтобы превратить то, что волнует тебя, в капитал, преуспеть в этом и продвинуться дальше.
Я считаю, что монотонная работа и отсиживание часов — это предательство всеобщего предпринимательского духа.
О людях
Очень важно искренне заботиться о людях. Вы не можете стать хорошим лидером не любите людей. Ведь только так вы способны увидеть лучшее в них.
Бизнес — это просто идея, придуманная для того, чтобы улучшить жизни людей.
О вызовах
Мой интерес к жизни вызван тем, что я устраиваю себе невероятные испытания и пытаюсь возвыситься над ними.
Моя самая большая мотивация? Просто продолжать бросать себе вызовы. Я смотрю на жизнь как на бесконечную учёбу в университете, которой у меня не было: каждый день я узнаю что-то новое.
И обо всём
Прежде всего хочется создать то, чем будешь гордиться. Это всегда было моей философией бизнеса. Я могу честно сказать, что никогда не занимался бизнесом, чтобы заработать. Если это единственный мотив, тогда лучше ничего не делать.
Я не воспринимаю работу как работу, а развлечения как развлечения. Это всё и есть жизнь.
А какие личности вдохновляют вас?
Итак очередной выпуск #likethebossdoes
Ричардом Брэнсоном (Richard Branson) сложно не восхищаться. Это уникальный предприниматель, мечтатель и победитель. Брэнсона часто приглашают выступить с лекциями, ведь его слова действительно вдохновляют. Эти цитаты бизнесмена добавят вам уверенности и энтузиазма.
О самобытности
Для меня заниматься бизнесом не значит надеть костюм и угождать стейкхолдерам. Речь о том, чтобы оставаться верным себе, своим идеям и фокусироваться на самом главном.
О позитивном настрое
Моё жизненное кредо — наслаждаться каждой минутой. Я никогда ничего не делаю с мыслью «О нет, сегодня я должен заняться этим».
Бизнесмен должен быть вовлечённым, ему должно быть весело. Это развивает творческие способности.
О предпринимательстве
Вся суть предпринимательства состоит в том, чтобы превратить то, что волнует тебя, в капитал, преуспеть в этом и продвинуться дальше.
Я считаю, что монотонная работа и отсиживание часов — это предательство всеобщего предпринимательского духа.
О людях
Очень важно искренне заботиться о людях. Вы не можете стать хорошим лидером не любите людей. Ведь только так вы способны увидеть лучшее в них.
Бизнес — это просто идея, придуманная для того, чтобы улучшить жизни людей.
О вызовах
Мой интерес к жизни вызван тем, что я устраиваю себе невероятные испытания и пытаюсь возвыситься над ними.
Моя самая большая мотивация? Просто продолжать бросать себе вызовы. Я смотрю на жизнь как на бесконечную учёбу в университете, которой у меня не было: каждый день я узнаю что-то новое.
И обо всём
Прежде всего хочется создать то, чем будешь гордиться. Это всегда было моей философией бизнеса. Я могу честно сказать, что никогда не занимался бизнесом, чтобы заработать. Если это единственный мотив, тогда лучше ничего не делать.
Я не воспринимаю работу как работу, а развлечения как развлечения. Это всё и есть жизнь.
А какие личности вдохновляют вас?

2019 November 04
Пока у нас возмущаются или смеются на тему 4-дневной рабочей недели, в японском офисе Микрософта проверили идею экспериментально: встречи стали короче и продуктивней, а люди — довольней ;)
https://mashable.com/article/microsoft-japan-4-day-work-week-trial-3-day-weekend/?europe=true
https://mashable.com/article/microsoft-japan-4-day-work-week-trial-3-day-weekend/?europe=true

2019 November 12
Друзья я жив, но не бываю в телеге и прочих сетях
вот интересная статья:
https://vc.ru/links/91666-teachable-machine-veb-prilozhenie-dlya-sozdaniya-modeley-mashinnogo-obucheniya-bez-znaniy-koda-ot-google?fbclid=IwAR0kHlIWKqSkn5p-XALGnarbSWdBs4aEu6ntqPO584iZTV35xtB6UyrY5kg
вот интересная статья:
https://vc.ru/links/91666-teachable-machine-veb-prilozhenie-dlya-sozdaniya-modeley-mashinnogo-obucheniya-bez-znaniy-koda-ot-google?fbclid=IwAR0kHlIWKqSkn5p-XALGnarbSWdBs4aEu6ntqPO584iZTV35xtB6UyrY5kg

Новости скоро! Очень много работы !)

2019 November 14
Питер Друкер
«Эффективный руководитель»
Читаю отличную книжку для руководителей, если вам не приходится руководить персоналом, а только продуктом она все равно будет вам полезна.
Существует пять основных методик, «пять привычек», которые необходимо выработать руководителю, чтобы работать эффективно:
1. Эффективные руководители знают, на что расходуется их время. Они систематически трудятся над управлением той малой долей своего времени, которую они действительно могут контролировать.
2. Эффективные руководители концентрируются на достижениях, выходящих за рамки их организаций. Они нацелены не на выполнение работы как таковой, а на конечный результат. Прежде чем приступить к выполнению того или иного задания, эффективный руководитель задает себе вопрос: «Каких результатов от меня ожидают?» Сам процесс работы, не говоря уже о конкретных методах ее выполнения, отходит для него на второй план.
3. Эффективные руководители развивают сильные стороны – свои собственные, своих начальников, коллег, подчиненных. В сложных ситуациях они полагаются именно на сильные стороны и не зацикливаются на слабых. Они не начинают с задач, которые не в состоянии решить.
4. Эффективные руководители сосредотачиваются на нескольких крупнейших областях, где отличная работа приведет к выдающимся результатам. Они заставляют себя определять приоритеты и не отступать от принятых решений. Они знают, что у них нет иного выбора, кроме как вначале заняться делами первостепенной важности, второстепенными же не заниматься никогда. Иначе не будет сделано ничего.
5. Наконец, эффективно работающие руководители принимают эффективные решения. Они знают, что правильные решения – это не что иное, как система, – ряд правильных шагов в правильной последовательности. Они знают, что эффективное решение – это всегда суждение, основанное на «несовпадении мнений», а не на «консенсусе в отношении фактов». И им известно, что быстро принятое решение – это ошибочное решение. Решений должно быть немного, но фундаментальных. Необходима правильная стратегия, а не изобретательные приемы.
Вот основные составляющие эффективной работы руководителя – и главные темы данной книги
Скачать и читать: https://t.me/watchandread/150
«Эффективный руководитель»
Читаю отличную книжку для руководителей, если вам не приходится руководить персоналом, а только продуктом она все равно будет вам полезна.
Существует пять основных методик, «пять привычек», которые необходимо выработать руководителю, чтобы работать эффективно:
1. Эффективные руководители знают, на что расходуется их время. Они систематически трудятся над управлением той малой долей своего времени, которую они действительно могут контролировать.
2. Эффективные руководители концентрируются на достижениях, выходящих за рамки их организаций. Они нацелены не на выполнение работы как таковой, а на конечный результат. Прежде чем приступить к выполнению того или иного задания, эффективный руководитель задает себе вопрос: «Каких результатов от меня ожидают?» Сам процесс работы, не говоря уже о конкретных методах ее выполнения, отходит для него на второй план.
3. Эффективные руководители развивают сильные стороны – свои собственные, своих начальников, коллег, подчиненных. В сложных ситуациях они полагаются именно на сильные стороны и не зацикливаются на слабых. Они не начинают с задач, которые не в состоянии решить.
4. Эффективные руководители сосредотачиваются на нескольких крупнейших областях, где отличная работа приведет к выдающимся результатам. Они заставляют себя определять приоритеты и не отступать от принятых решений. Они знают, что у них нет иного выбора, кроме как вначале заняться делами первостепенной важности, второстепенными же не заниматься никогда. Иначе не будет сделано ничего.
5. Наконец, эффективно работающие руководители принимают эффективные решения. Они знают, что правильные решения – это не что иное, как система, – ряд правильных шагов в правильной последовательности. Они знают, что эффективное решение – это всегда суждение, основанное на «несовпадении мнений», а не на «консенсусе в отношении фактов». И им известно, что быстро принятое решение – это ошибочное решение. Решений должно быть немного, но фундаментальных. Необходима правильная стратегия, а не изобретательные приемы.
Вот основные составляющие эффективной работы руководителя – и главные темы данной книги
Скачать и читать: https://t.me/watchandread/150

2019 November 29
Ли Седоль уходит из го, потому что после проигрыша нейросетке больше не видит смысла заниматься делом, которому посвятил жизнь.
https://en.yna.co.kr/view/AEN20191127004800315
Друзья! Простите, небольшой оффтопик. Даже если вы чемпионы, трансгуманисты и сверхчеловеки, даже если считаете себя монадой в оболочке из останков древних сверхновых, не стоит забывать, что на самом деле вы сделаны из мяса, а на дворе конец ноября.
Вполне возможно, небо не рушится на землю, а всего лишь пасмурное. Те, кто думает, что они бессмысленные и бесполезные, скорее всего, просто устали. Авторы нашего канала напоминают, что нас всех кто-то любит, каждое сознание бесценно согласно теореме о запрете квантового клонирования, а весна неизбежна, как сингулярность.
Чмоки.
https://en.yna.co.kr/view/AEN20191127004800315
Друзья! Простите, небольшой оффтопик. Даже если вы чемпионы, трансгуманисты и сверхчеловеки, даже если считаете себя монадой в оболочке из останков древних сверхновых, не стоит забывать, что на самом деле вы сделаны из мяса, а на дворе конец ноября.
Вполне возможно, небо не рушится на землю, а всего лишь пасмурное. Те, кто думает, что они бессмысленные и бесполезные, скорее всего, просто устали. Авторы нашего канала напоминают, что нас всех кто-то любит, каждое сознание бесценно согласно теореме о запрете квантового клонирования, а весна неизбежна, как сингулярность.
Чмоки.
